Retrieval-Augmented Language Model pre-training

What is Retrieval-Augmented Language Model pre-training?
A Retrieval-Augmented Language Model, also referred to as REALM or RALM, is an artificial intelligence (AI) language model designed to retrieve text and then use it to perform question-based tasks.
Pre-training such a system refers to the process of first training the model for one task before training the model to work on another related task or data set. Using an already adjacently trained model is a fast and efficient way to build AI applications, giving the model essentially a head-start in training, when compared to training a new model from scratch. The language model pre-training process also aids in capturing a large amount of world knowledge that can be crucial for neural network natural language processing (NLP) tasks, such as question answering.
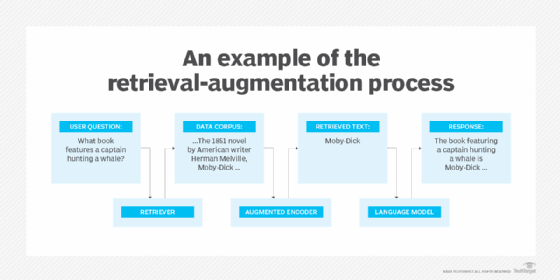
Google introduced retrieval-augmented language model pre-training in 2020 in a document about using masked language models, like BERT, to perform open-book question answering. This process uses the corpus -- or the collection of data used to train the AI -- of documents with a language model architecture. This helps the REALM model find documents, their most relevant passages and return the relevant data for information extraction.
Basic REALM architecture
Retrieval-augmented models typically use a semantic retrieval mechanism. For example, REALM uses a knowledge retriever and a knowledge-augmented encoder. The knowledge retriever helps the large language model (LLM) -- a type of AI algorithm that uses deep learning techniques and massively large data sets to understand, summarize, generate and predict new content -- find and focus on specific text from a large knowledge corpus. When the user inputs a prompt, the knowledge retriever's goal is to identify relevant documents. A knowledge-augmented encoder tool is then used to retrieve the correct data from the text. The text and the original prompt are then passed to the LLM to answer the user's initial question.
This article is part of
What is GenAI? Generative AI explained
Stages in a pre-training program
Pre-trained programs require a machine learning model and two different data sets. The basic stages include the following:
- Train the machine learning model with its initial training data set. Initial training stages typically consist of an assessment stage to determine if training is required; a development stage, where the training material, environment and various tools are developed or chosen; a delivery stage where training begins; and an evaluation benchmark stage where the effectiveness of the training is determined. A diverse initial training data set exposes the model to various features, patterns and representations of data.
- Define the model parameters and how it uses the initial training data set. As an example, in REALM, pre-training and fine-tuning tasks are formalized as a retrieve-then-predict generative process.
- Begin training the model on the new data set. It's important that the new data set is similar in form to the model's initial training. For example, training a model that's already trained to predict traffic metrics wouldn't be useful if it's then trained to detect objects. But a model trained on object detection would be useful for creating a model that can identify animals.
Pre-training is typically applied for transfer learning, classification or feature extraction.
- Transfer learning uses the data gained from one machine learning model for another model.
- Classification refers to a machine learning model that's trained for classification-level tasks, such as for classifying images.
- Feature extraction identifies and extracts relevant data features from a data set, where the extracted features are then used in another model.
Pros and cons of pre-training
Benefits of pre-training include the following:
- Ease of use. Developers don't need to create models from scratch. They can instead find a pre-trained model that was trained on a similar task and train it again to the specific task being worked on.
- Optimizes performance. A pre-trained model can reach optimized performance faster, as it might already know what parameters will likely create good results.
- Doesn't require large amounts of training data. Pre-trained models don't require as much training data as building a model from scratch. Additionally, models available online are likely to already have been trained on extremely large data sets.
- Improves NLP tasks. REALM pre-training improves the efficiency of NLP-related tasks, such as those for question answering.
Potential downsides to pre-training, however, might include the following:
- Requires fine-tuning. The fine-tuning process can be resource-intensive and require time for effective tuning.
- Produces ineffective results. Using an already trained model for a task that's too different from its initial task won't produce effective results in training.
Retrieval-augmented generation, retrieval-augmented language model and LLMs
Retrieval-augmented language models, LLMs and retrieval-augmented generation (RAG) are all closely related. REALM and RAG are both AI models and frameworks that work with LLMs.
But where REALM is a language model designed to retrieve text from a corpus of initial training data and then use it to answer knowledge-intensive question-based tasks, RAG is designed to access external information, separate from its initial training data. For example, RAG can retrieve data from external sources such as external knowledge bases, databases or the internet.
LLM models typically have a training end date, after which the LLM is unaware of any new events or developments. This means that LLMs typically aren't working with the newest, most up-to-date information -- essentially freezing an LLM's knowledge at a point in time. RAGs get around this limitation by pulling from external sources of information in real time. This improves the quality of responses while reducing AI hallucinations. If an AI model like ChatGPT used RAG, it wouldn't be limited based on its training end date.
REALM can also be paired with zero-shot learning, which is a machine learning concept that recognizes samples from classes that the model wasn't initially trained on.
Pre-training vs. fine-tuning
While pre-training is the concept of training a previously trained machine learning model on a similar task with new training data, fine-tuning refers to the process of refining a pre-trained model to work on particular tasks. Fine-tuning uses a smaller data set with the goal of adjusting and specializing the model to fit a specific task. An example of this is fine-tuning an LLM for sentiment analysis.
Both pre-training and fine-tuning as concepts aren't exclusive, however. For example, a REALM model can be pre-trained and then later fine-tuned. Fine-tuning lets the model take advantage of its broad knowledge from pre-training while also specializing in a specific target task. Fine-tuning also provides better performance in its task.
Learn more about RAG and other currently developing AI and machine learning trends.






