
Getty Images
10 ways to reduce your MTTR
Mean time to repair is a critical metric for BCDR professionals. Learn how to calculate and reduce MTTR with this tip.

Business continuity and disaster recovery pros need a way to determine how long something will take to fix, whether it is a business process, IT system or hardware component. MTTR is one helpful metric they can rely on.
Mean time to repair is a widely used metric that estimates the average time a system is likely to need for repair before it can resume normal operation. It is also sometimes referred to as the mean time to resolve, recover or respond.
Regardless of what you call it, the lower the MTTR value, the easier the item will be to fix. When managing systems, technologies or processes, the goal is to reduce the average time something will need for repair. If, for example, a system's MTTR is 0, its users will experience much less downtime than those with a system that has a positive value for its MTTR.
When the goal is uninterrupted operation, a low MTTR value means that the item in question -- if it fails -- will be fairly easy to repair and will take minimal time to return to normal operations. In this article, learn how to reduce MTTR, why it's important to keep that metric low and some tips for calculating MTTR.
How to reduce MTTR
A lower MTTR means that a system or process performs well, and this is particularly important for business continuity and disaster recovery (BCDR) professionals.
Reducing MTTR for specific items begins with setting a baseline MTTR that forms the starting point. Subsequent MTTR calculations compared with the baseline will show BCDR teams and admins if progress in system and process performance has been made.
There are several actions that an organization can take to reduce MTTR values of critical operations. The following are 10 ways to track and reduce MTTR:
- Build and maintain a supply of spare parts and components in case a production component fails.
- Conduct regular tests and performance reviews to make sure that systems work.
- Perform a business impact analysis to indicate which systems and processes are most critical, and calculate MTTR to monitor their performance.
- Add MTTR to other performance metrics, such as recovery time objective and recovery point objective.
- Deploy an optimized incident response plan that protects mission-critical assets and enables rapid response to any malfunction.
- Establish special rapid response teams that respond to system and process outages beyond an incident response team.
- Install monitoring systems with sensors that can provide alerts when systems cease to perform properly.
- Streamline help desk resources to simplify the reporting process, including problem detection and ticket submission.
- Fully train equipment repair teams and train personnel in the event that those teams are unavailable.
- Update the organization's change management process to minimize the chance for error.
Why is a low MTTR important?
MTTR is a critical element in BCDR plans and can become an essential metric to make sure that systems perform without interruption.
Assets with low MTTR are less likely to fail, and if they do, their ability to recover and resume normal operations will take a minimal amount of time. By contrast, if BCDR teams find that a system has high MTTR, such as four to five days, they should probably replace it.
Updates and newer components are other options for reducing MTTR in an existing system. Management will need to decide at what point a high MTTR necessitates a complete replacement or redesign of the item.
How to calculate MTTR
MTTR is an average of the analysis of several items. For a specific period of time, such as a day, week or month, and for each repair that IT performed, the amount of time each repair takes is added to other, similar repair values. That value, usually expressed in hours, is then divided by the number of unplanned or unscheduled repair events during the analysis period -- meaning all events that require repair that were not meant to occur. Scheduled maintenance time frames are not included in MTTR calculations.
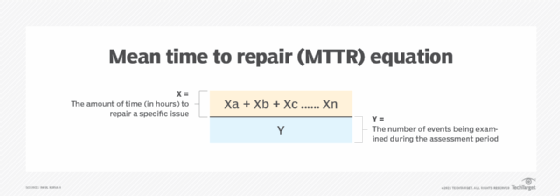
In practice, BCDR teams use this calculation on a series of events that require repair. This will provide them with the MTTR. From there, it is easier to get an idea of how much they need to reduce MTTR or if current systems are sufficient.
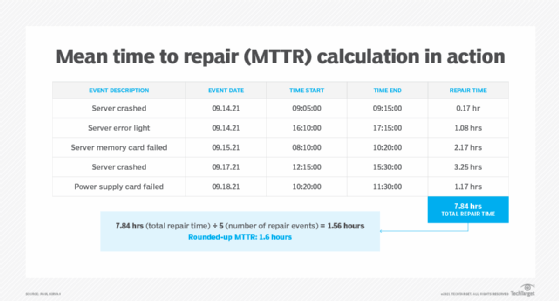
While this calculation seems relatively simple, and BCDR teams can easily configure it with a spreadsheet, potential flaws and errors can occur. For example, the MTTR equation assumes that tasks are performed sequentially by appropriately trained personnel. If the order of tasks is changed, if multiple tasks happen at once or if the person performing the tasks isn't properly trained, the calculation could be incorrect.
MTTR vs. MTBF
Often used in conjunction with MTTR is mean time between failures. MTBF is another important performance and maintenance metric for BCDR teams.
MTTR deals with the average time needed to repair something, but MTBF expresses the average time between occurrences of system and process failures. This metric indicates the reliability of a system or process.
A higher MTBF value indicates that the system or process is less likely to fail, but might still experience infrequent outages. If a system has an MTBF value of five to 10 hours, for example, downtime is far more likely than if the MTBF value were one to two years. Technology professionals aim for as high an MTBF value as possible, but must be prepared for more frequent failures.

Both MTTR and MTBF provide measurements on the performance and reliability of a system, process or other activity. Values for each metric, as described, can indicate situations where remedial action is necessary.
Paul Kirvan, FBCI, CISA, is an independent consultant and technical writer with more than 35 years of experience in business continuity, disaster recovery, resilience, cybersecurity, GRC, telecom and technical writing.






