More organizations are turning to DataOps to bolster their data management operations. Learn how to build a team with the right people to ensure DataOps success.
A DataOps strategy is heavily reliant on collaboration as data flows between managers and consumers throughout the business. Collaboration is essential to DataOps success, so it's important to start with the right team to drive these initiatives.
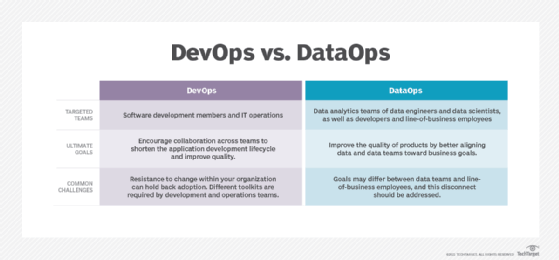
It's natural to think of DataOps as simply DevOps for data -- not quite. It would be more accurate to say that DataOps is trying to achieve for data what DevOps achieves for coding: a dramatic improvement in productivity and quality. However, DataOps has some other problems to solve, in particular how to maintain a mission-critical system in continuous production.
The distinction is important when it comes to thinking about putting together a DataOps team. If the DevOps approach is a template, with Product Managers, Scrum Masters and Developers, the focus will end up on delivery. DataOps also needs to focus on continuous maintenance and requires some other frameworks to work with.
One key influence on DataOps has been Lean manufacturing techniques. Managers often use terms taken from the classic Toyota Production System, which has been much studied and imitated. There're also terms like data factory when talk starts about data pipelines in production.
This approach requires a distinctive team structure. Let's first look at some roles within a DataOps team.
Key roles for DataOps
The roles described here are for a DataOps team deploying data science in mission-critical production.
What about teams who are less focused on data science? Do they need DataOps, too, for example, for a data warehouse? Certainly, some of the techniques may be similar, but a traditional team of extract, transform and load (ETL) developers and data architects is probably going to work well. A data warehouse, by its nature, is less dynamic and more constant than an Agile pipelined data environment. The following DataOps team roles handle the rather more volatile world of pipelines, algorithms and self-service users.
Let's start with defining the roles required for these new analytics techniques.
The data scientist
Data scientists do research. If an organization knows what they want and they just need someone to implement a predictive process, then get a developer who knows their way around algorithms. The data scientist, on the other hand, explores for a living, discovering what is relevant and meaningful as they do.
In the course of exploration, a data scientist may try numerous algorithms, often in ensembles of diverse models. They may even write their own algorithms.
The DataOps team can make the difference between an enterprise who occasionally does cool things with data and an enterprise that runs efficiently and reliably on data, analytics and insight.
The key attributes for this role are restless curiosity and an interest in the domain, as well as technical insight -- especially in statistics -- to understand the significance of what they discover and the real-world impact of their work.
This diligence matters. It is not enough to find one good model and stop there because business domains rapidly evolve. Also, while everyone may not work in areas with compelling ethical dilemmas, data scientists in every domain sooner or later come across issues of personal or commercial privacy.
This is a technical role, but don't overlook the human side, especially if the organization is only hiring one data scientist. A good data scientist is a good communicator that is able to explain findings to a nontechnical audience, often executives, while being straightforward about what is and is not possible.
Finally, the data scientist, especially one working in a domain which is new to them, is unlikely to know all the operational data sources -- ERP, CRM, HR systems and so on -- but they certainly need to work with the data. In a well-governed system, they may not have direct access to all the unprocessed data of an enterprise. They need to work with other roles who understand the source systems better.
The data engineer
Generally, it is the data engineer who moves data between operational systems and the data lake -- and, from there, between zones of the lake such as raw data, cleansed and production areas.
The data engineer also supports the data warehouse, which can be a demanding task in itself as they must maintain history for reporting and analysis while providing for continuous development.
At one time, the data engineer may have been called a data warehouse architect or ETL developer, depending on their expertise. But data engineer is the new term of art, and it captures better the operational focus of the role in DataOps.
The DataOps engineer
Another engineer? Yes and one focused on operations. But the DataOps engineer has a different area of expertise: supporting the data scientist.
The data scientist's skills focus on modeling and deriving insight from data. However, it is common to find that what works well on the workbench can be difficult or expensive to deploy into production. Sometimes, an algorithm runs too slowly against a production data set but also uses too much compute or storage to scale effectively. The DataOps engineer helps here by testing, tweaking and maintaining models for production.
As part of this, the DataOps engineer knows how to keep a model scoring accurately enough over time as data drifts. They also know when to retrain the model or reconceptualize it, even if that work falls to the data scientist.
The DataOps engineer keeps models running within budget and resource constraints that they likely understand better than anyone else on the team.
The data analyst
In a modern organization, the data analyst may have a wide range of skills, ranging from technical knowledge to aesthetic understanding of visualization to so-called soft skills, such as collaboration. They are also less likely to have had much technical training compared to, say, a database developer.
Their data ownership -- and influence -- may depend less on where they sit in the organizational hierarchy and more on their personal commitment and their willingness to take ownership of a problem.
These people are in every department. Look around. Someone is "the data person," who, regardless of job title, knows where the data is, how to work with it and how to present it effectively.
To be fair, this role is becoming more formalized today, but there are still a large number of data analysts who have grown into the role from a business rather than technical background.
The executive sponsor
Is the executive sponsor a member of the team? Perhaps not directly, but the team won't get far without one. A C-level sponsor can be critical for aligning the specific work of a DataOps team with the strategic vision and the tactical decisions of the enterprise. They can also ensure the team has budget and resources with long-term goals in mind.
The difference between DevOps and DataOps
Tailor the team to fit the organization
Few organizations can, or will, immediately stand up a team of four or more just for DataOps. The capabilities and value of team must grow over time.
How, then, should a team grow? Who should be the first hire? It all depends on where the organization is starting from. But there needs to be an executive sponsor from day zero.
It is unlikely the team is starting from scratch. Organizations need DataOps precisely because they already have work in progress that needs to be better operationalized. They may have started to look at DataOps because they have data scientists stretching the boundaries of what they can manage today.
If so, the first hire should be a DataOps engineer because it is their role to operationalize data science and make it manageable, scalable and comprehensive enough to be mission-critical.
On the other hand, it is possible an organization has a traditional data warehouse, and there are data engineers involved and data analysts downstream from them. In this case, the first DataOps team position would be a data scientist for advanced analysis.
An important question is whether to create a formal organization or a virtual team. This is another important reason for the executive sponsor, who may have a lot of say in the answer. Many DataOps teams start as virtual groups who work across organizational boundaries to ensure data and data flow are reliable and trustworthy.
Whether loosely or tightly organized, these discrete disciplines grow in strength and impact over time, and their strategic direction and use of resources will cohere into a consistent framework for exploration and delivery. As this happens, the organization can add more engineering for scale and governance and more scientists and analysts for insight. At this point, wherever the organization started, the team is likely to become more formally organized and recognized.
It's an exciting process. The DataOps team can make the difference between an enterprise that occasionally does cool things with data and an enterprise that runs efficiently and reliably on data, analytics and insight.