
folienfeuer - Fotolia
How parallelization works in streaming systems
Dive into this book excerpt from 'Grokking Streaming Systems' and learn the crucial role the parallelization process plays in the design of a streaming system.
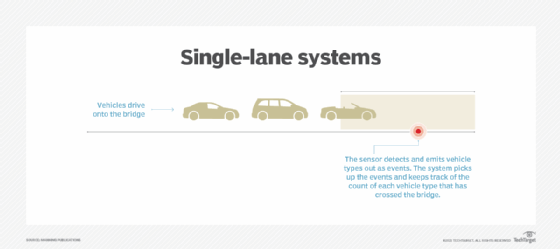
Detecting traffic with one sensor emitting traffic events is an acceptable way to collect the traffic data when there's a single-lane bridge. Tim is a true believer of new technologies and interested in using them to solve problems in the businesses he owns. In recent years, he's become curious about big data technologies, especially stream processing.
Naturally, Tim wants to make more money, so with a bridge he opts to build more lanes on the bridge. In essence, Tim is asking for the streaming job to scale in the number of traffic events it can process at one time.
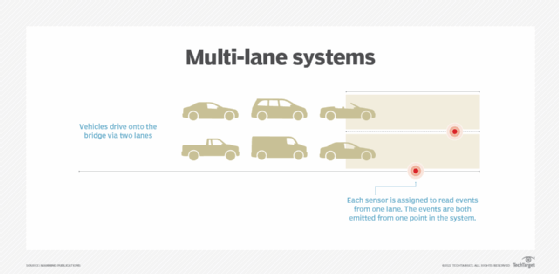
Tim's new bridge has two lanes on each side with one sensor reading from each lane. The events still emit out, as they come from one unified system.
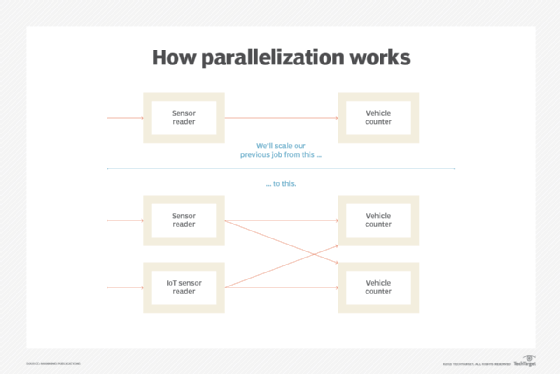
A typical solution in computer systems to achieve higher throughput is to spread out the calculations onto multiple processes, which is called parallelization. Similarly, in streaming systems, the calculation can be spread out to multiple instances. You can imagine with our vehicle count example that having multiple lanes on the bridge and having more toll booths could be helpful to accept and process more traffic and to reduce waiting time.
 Click to buy
Grokking
Click to buy
Grokking Streaming Systems
from Manning Publications.
Take 35% off any format by
entering ttfischer into the
discount code box at checkout.
Parallelization is an important concept
Parallelization is a common technique in computer systems. The idea is that a time-consuming problem can often be broken into smaller sub-tasks that can be executed concurrently, or at the same time. Then we can have more computers working on the problem cooperatively to reduce the total execution time.
Why it's important
If there are 100 vehicle events waiting in a queue to be processed, the single vehicle counter must process all of them one by one. In the real world, there could be millions of events every second for a streaming system to process. Processing these events one by one isn't acceptable in many cases, and parallelization is critical for solving large-scale problems.
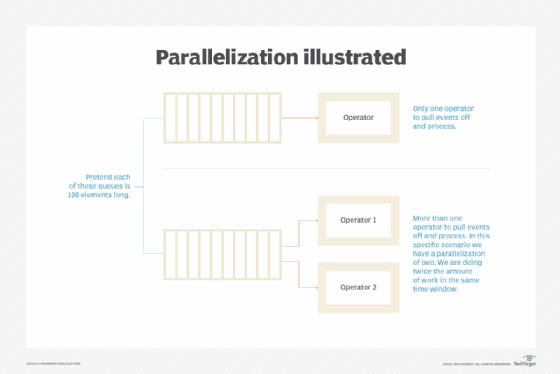
New concepts: Data parallelism
It isn't fast enough to solve the counting problem with one computer. It's a reasonable idea to assign each vehicle event to a different computer, allowing all the computers to work on the calculation in parallel. This way you process all vehicles in one step, instead of processing them one by one in 100 steps. The throughput is 100 times greater. When there is more data to process, more computers instead of one "bigger" computer can be used to solve the problem faster. This is called "horizontal scaling."
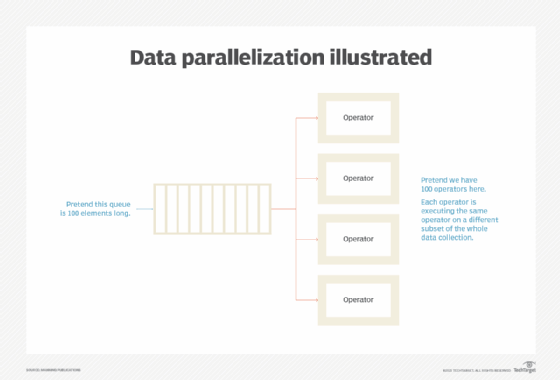
New concepts: Data execution independence
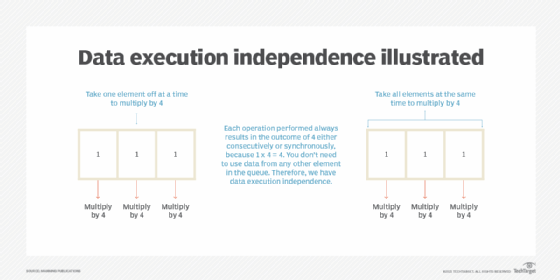
Say the words data execution independence out loud and think about what it could mean. This is quite a fancy term, but it isn't as complex as you think.
Data execution independence regarding streaming means the end result is the same no matter the order of how calculations or executions are performed across data elements. For example, in the case of multiplying each element in the queue by four, they'll have the same result whether they're done at the same time or one after another. This independence allows for the use of data parallelism.
New concepts: Task parallelism
Data parallelism is critical for many big data systems, as well as general distributed systems, because it allows developers to solve problems more efficiently with more computers. In addition to data parallelism, there's another type of parallelization: task parallelism. Task parallelism is also known as function parallelism. In contrast to data parallelism, which involves running the same task on different data, task parallelism focuses on running different tasks on the same data.
The sensor reader and vehicle counter components keep running to process incoming events. When the vehicle counter component is processing (counting) an event, the sensor reader component takes a different, new event at the same time. The two different tasks work concurrently. From events' point of view, an event is emitted from the sensor reader, then it's processed by the vehicle counter component.
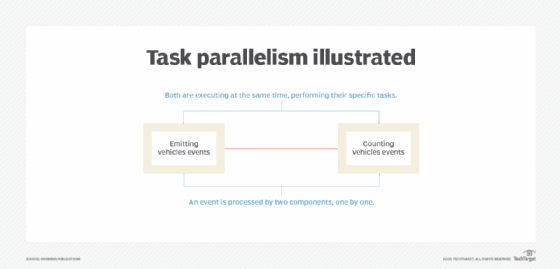
Data parallelism vs. task parallelism
A quick summary:
- Data parallelism is when the same task is executed on different event sets at the same time.
- Task parallelism represents that different tasks are executed at the same time.
Data parallelism is widely used in distributed systems to achieve horizontal scaling. In these systems, it's relatively easy to increase parallelization by adding more computers. On the other side, task parallelism normally requires manual works to break the existing processes into multiple steps in order to increase parallelization.
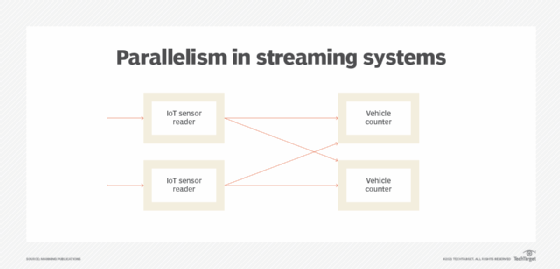
Streaming systems are combinations of data parallelism and task parallelism. In a streaming system, data parallelism is about creating multiple instances of each component, and task parallelism is about breaking the whole process into different components to solve the problem.
Now we're going to learn how to apply the data parallelism technique and create multiple instances of each component.
In most cases, if you see the term parallelization or parallelism without the terms data or task in streaming systems, it typically refers to data parallelism. This is the convention we are going to apply in this article. Remember that both parallelisms are critical techniques in data processing systems.
Parallelism and concurrency: Is there a difference?
Parallelization is the term we've decided to use when explaining how to modify your streaming jobs for performance and scale. More explicitly in the context of this article, parallelism refers to the number of instances of a specific component. Or you could say parallelism is the number of instances running to complete the same task. Concurrency, on the other hand, is a general word that refers to two or more things happen at the same time.
It should be noted that we use threads in our streaming framework to execute different tasks, but in real-world streaming jobs you'd typically run multiple physical machines somewhere to support your job. In this case you could call it parallel computing. It could be a question for some readers if parallelization is the accurate word when we're only referring to code which is running on a single machine. Yet another question we asked ourselves -- is this correct for us to write about? We have decided to not cover this question. After all, the goal for this article is that by the end of it you could comfortably talk about topics in streaming. Overall you should know that parallelization is a huge component of streaming systems, and it's important for you to get comfortable talking about the concepts and understanding the differences well.
Parallelizing the job
This is a good time to review the state of the last streaming job we studied. You should have a traffic event job that contains two components: a sensor reader and a vehicle counter. As a refresher, the job can be visualized as the below image.
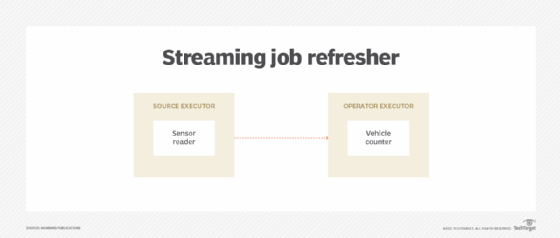
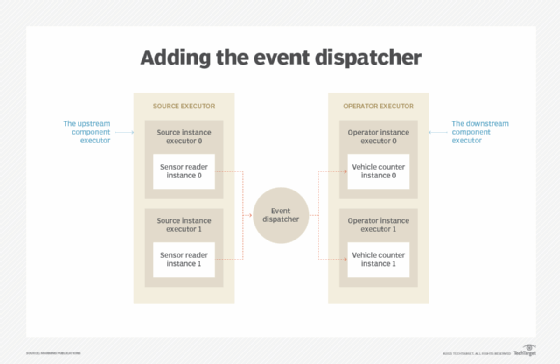
Let's introduce a new component we decided to call the event dispatcher. It allows us to route data to different instances of a parallelized component. The image below is an end result of reading through this article and working through how we build up the job.
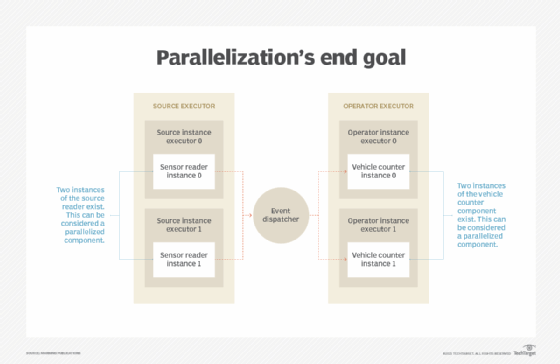
Parallelizing components
The below image shows the end goal of how we want to parallelize the components in the streaming job. The event dispatcher helps us distribute the load across downstream instances.
If you want to learn more about the book Grokking Streaming Systems, follow the link at the top of the article.
Dig Deeper on Data management strategies
-
![]()
Why Apache Kafka is the AI workflow you (probably) already have
By: Adrian Bridgwater
-
![]()
How to use LangChain for LLM application development
By: Kerry Doyle
-
![]()
What is stream processing? Introduction and overview
By: Rahul Awati
-
![]()
How to use parallel streams in Java with virtual threads
By: A N M Bazlur Rahman



