Google boosts AlloyDB with added vector search capabilities
New features address the accuracy and performance of the in-database vector searches that discover relevant data for feeding and training AI models and applications.
Google Cloud launched new features in its AlloyDB database designed to improve the vector search capabilities that help fuel AI development pipelines.
Included are inline filtering to upgrade the speed and accuracy of filtered searches, new observability and management features, and vector index distribution statistics to provide users with rapidly changing real-time information that lets them address pipeline stability and performance.
Together, the three new features unveiled on Feb. 25 demonstrate the incremental evolution of vector search, according to Tony Baer, principal at dbinsight.
The enhancements to AlloyDB's vector support are good examples of how we learn from experience. [They] represent an important incremental improvement focusing on optimizing and improving the quality of vector queries.
Tony BaerPrincipal, dbinsights
Previously, evolutions included the additions of vector storage and similarity searches, followed by the extension of the SQL query language to blend structured and unstructured data. Now, the new AlloyDB features build on those advancements.
"The enhancements to AlloyDB's vector support are good examples of how we learn from experience," Baer said. "[They] represent an important incremental improvement focusing on optimizing and improving the quality of vector queries."
Traditional relational databases went through a similar evolution, he continued.
"It's history repeating itself," Baer said. "When relational databases emerged, the next step was realizing that not all queries are alike, and that we needed different ways of optimizing them. That's what the trio of features … target."
Google unveiled AlloyDB in May 2022, before making initial vector search capabilities generally available in February 2024.
New capabilities
Generative AI has the potential to make workers better informed and more efficient. As a result, enterprises have rapidly increased their investments in AI development over the two-plus years since OpenAI's November 2022 launch of ChatGPT marked a significant improvement in generative AI large language models (LLMs).
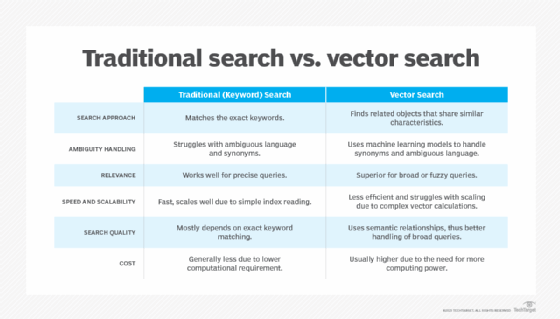
However, for LLMs to make workers better informed and more efficient, they need to be combined with relevant proprietary data to understand an individual enterprise's operations. Discovering the relevant information to inform an application amid potentially billions of data points is onerous. Vector search is a means of automating relevant data discovery.
Vectors are numerical representations of data assigned by algorithms to make data -- including unstructured data such as text, images and audio files -- searchable on a large scale. Using vectors, developers and engineers can run similarity and keyword searches to find the right data for an application, feed that data into retrieval-augmented generation (RAG) pipelines and combine it with LLMs to train generative enterprise-specific AI tools.
Because of the role vector search now plays in AI development, many data management vendors have added vector search capabilities. For example, vector search is now part of the Oracle Database Platform and is prominent in AWS' database strategy.
Given the importance of vector search, and because the features Google is adding to AlloyDB improve its in-database vector search capabilities, the new capabilities are significant for AlloyDB customers, according to David Menninger, an analyst at ISG's Ventana Research.
"Vector search is core to RAG capabilities and is nearly universal in generative AI workloads," Menninger said. "So, while not earth-shattering, [the new features] are certainly helpful for one of the most popular types of workloads right now."
Specifically, the new features include the following:
Inline filtering for AlloyDB's ScaNN Index -- An approximate nearest neighbor (ANN) vector search -- to improve the query performance of filtered vector searches by combining vector indexes and traditional indexes on metadata columns.
Observability and management tools -- including a recall evaluator that monitors the percentage of relevant results when performing a search query -- that aim to ensure stable search performance and quality.
Vector search distribution statistics for the ScaNN Index to provide users with insight into changes in data in real time so they can maintain stable vector search performance.
While all are beneficial, inline filtering and the recall evaluator stand out as perhaps the most significant additions, according to Baer.
"Inline filtering is an important addition to the palette for vector query optimization, while recall evaluator is a critical yardstick and corrective for query reliability," he said. "Both are equally important."
Beyond representing the evolution of AlloyDB's vector search capabilities, the new features demonstrate incremental innovation and will force vector database competitors to respond, Baer continued.
"This is the opening shot of what we expect to see more of this year," he said. "I viewed vector index optimizations as the most likely next steps in refining vector data stores, but AlloyDB's enhancements with filtering and recall show there are many paths of attack."
Menninger likewise highlighted the inline filtering capabilities.
By targeting ANN searches that discover data points with some overlapping characteristics rather than exact neighbor searches that find more precisely matching data, Google is promoting speed over accuracy. But speed is sometimes preferable to precision, according to Menninger.
"The ScaNN index provides flexibility that didn't exist before," he said. "The tradeoff is that the results may not … find all the 'nearest neighbors,' but that may not be as important as delivering a reasonable set of similar items faster."
Next steps
While the new features improve AlloyDB's vector search capabilities and represent the next steps in the overall evolution of vector search, there is still room for more growth, according to Baer.
Now that recall evaluation is available in AlloyDB to monitor the percentage of relevant results from a given ScaNN index query, Google could go further by adding tools that measure the accuracy of different vector index queries.
"A logical next step is different index types geared for different levels of recall," Baer said. "That's because, depending on the nature of the task, not all vector queries will require the same level of recall."
Menninger, meanwhile, suggested that Google could make AlloyDB more attractive to potential new customers by adding new migration capabilities. The tech giant previously introduced Database Migration Service to automate converting code and database schema from Oracle databases to AlloyDB. Google could do the same for databases from IBM, Microsoft and SAP, among others.
"The conversion process is generally the biggest obstacle when migrating from one database to another," Menninger said.
Eric Avidon is a senior news writer for Informa TechTarget and a journalist with more than 25 years of experience. He covers analytics and data management.