Originators form group to boost Presto SQL query engine
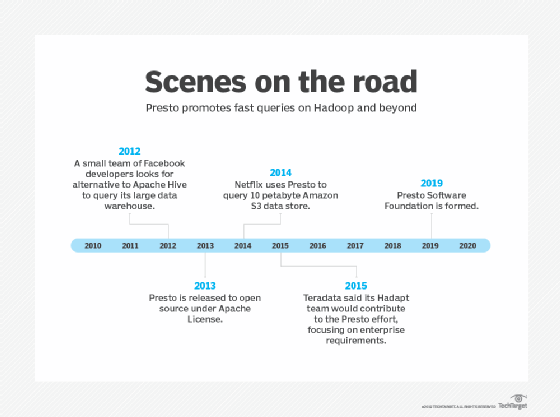
The Presto engine arose as an alternative to Hive for big data queries. Now, the Presto Software Foundation has formed to promote the SQL query software's virtues.
The Presto SQL query engine is determined to break out from the crowded pack of open source analytics tools.
To that end, members of the original Facebook Presto development team have joined with others to form the Presto Software Foundation.
The new group's goal is to boost Presto's open source credentials, and ensure the software's quality and extensibility, while moving the Presto SQL query engine forward in mainstream organizations.
The software, which debuted in 2012, has found adherents at Airbnb, Uber, Walmart and other companies. Vendors supporting Presto include Arm Treasure Data, AWS, Google, Microsoft, Qubole, Starburst Data, Teradata, Varada and others.
The software has seen a steady climb. Presto ranks 41st in a relational database category comprising 136 systems, as measured in the latest edition of the DB-Engines popularity ranking.
Presto SQL query engine on rise
While it has seen an uptick in recent years, Presto still significantly trails Apache Hive, a predecessor Facebook framework for batch query processing. That sits at number 10 in the DB-Engines relational database ranking.
As an older tool, Apache Hive has a lead on the Presto SQL engine. Hortonworks and others have devoted energy to improving its performance for queries. Also, Apache Hive has been a key component in many widely used Hadoop software distributions. Other open source SQL engine entrants include Drill, Hawq, Impala and Spark.
The numbers of Presto users outside of Facebook have grown dramatically, according to Martin Traverso, a co-creator of the software, and a co-founder of the Presto Software Foundation, which was formally announced Jan. 30. He pointed to Lyft, Netflix, Twitter and others as exemplary Presto users.
"Now, among users there is a general dependency on the success of the project," Traverso said. "Going forward, we feel it is important that the project remain independent."
So, to assure useful technology roadmaps, transparency and clarity, Traverso continued, he and others decided to set up the not-for-profit organization. The foundation is considering Presto SQL engine roadmaps security models for cloud object storage, failover and recovery protocols and means to better support ETL workloads, he said.
The Presto SQL query engine arose within social media powerhouse Facebook. A foundation has formed to further Presto.
Multiple back ends
Traverso said Presto has made much progress since its first days as an ad hoc query alternative to batch Hive at Facebook. Meanwhile, the designers' decision early on to support execution on multiple data back ends has proved important.
Presto provides a SQL abstraction layer that allows access to data wherever it may be.
Justin BorgmanCEO, Starburst Data
Justin Borgman, CEO at Starburst Data, said the broad federated back-end capabilities of Presto -- for example, the ability to join log data stored in S3 with customer data stored in MySQL -- are a significant driver of interest. Outside of Facebook, Starburst technical staff forms the largest group of committers to the Presto project to date, Borgman said.
In fact, Starburst principals spearheaded much of the effort to enterprise-harden Presto. They served first at Hadapt, an early SQL on Hadoop player that Teradata bought in 2014. At Teradata, the Hadapt crew turned its attention to improving Presto's performance. The work was carried on at Starburst, which was spun out of Teradata in late 2017.
"Presto provides a SQL abstraction layer that allows access to data wherever it may be," Borgman said. This is useful as data lake architectures, which started out as Hadoop-based, are now moving to encompass cloud object storage, he continued.
The PostgreSQL of big data? Presto
For his part, Borgman said having an organization like the foundation -- one independent of corporate interests -- is an important step in the spread of the Presto SQL query engine.
He said he hopes the software could find a reception akin to popular open source databases -- potentially becoming something like "the PostgreSQL of big data analytics."
As tools for SQL on Hadoop analytics began appearing a few years ago, a steady stream became a small torrent. Now, as SQL on Hadoop morphs into SQL on anything, a foundation that focuses on Presto could help it stand out in that stream.