How to build an effective streaming data architecture
Data architecture can be tricky when it comes to real-time analytics. Clear objectives and scalability are important factors when determining the streaming data architecture you need.
Enterprises are being deluged with real-time data from a variety of sources, including web and mobile apps, IoT, market data and transactions. In theory, this should provide a wealth of information for improving customer experience, saving money and generating profits.
A proper real-time analytics architecture can help business managers and data scientists quickly test out new ideas to identify and scale up the best use cases.
Traditional analytics approaches rely on data being structured and stored in databases optimized for a particular class of query. Real-time analytics replicates this for data that is constantly changing and must be structured on the fly.
"Streaming analytics makes it possible to know and act upon events happening in a business at any given moment and use that information to make better business decisions," said Erik Riedel, senior vice president of compute and storage solutions at ITRenew, an IT consultancy.
At the same time, it's important to design a real-time analytics architecture that can respond and scale, rather than just building a one-off streaming analytics project.
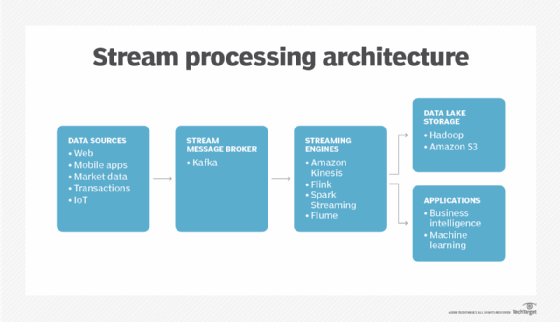
A breakdown of the streaming data process
Key questions that will shape your streaming data architecture
All streaming architectures will have the same core components. These include a streaming data aggregator, a broker for managing access to this data and an analytics engine. But these components need to be customized for different kinds of enterprises and use cases.
"The specific data architecture needed for streaming will vary with data sizes, transaction frequency and the complexity of the questions that are being asked of the analytics," Riedel said.
For example, there can be big differences in the requirements for providing real-time analytics data to a small number of analysts at the company's headquarters for quarterly trend spotting compared with providing different kinds of real-time analytics across a larger enterprise.
Key questions to consider include the following:
What is the data size?
What is the update or transaction frequency?
What is the query complexity?
What is the number of analysts or applications it will serve?
Riedel said the answers to these questions can impact system design all the way down to the hardware level in terms of data storage, RAM and distributed memory access. Geographic distribution of stream ingestion can add additional pressure on the system, since even modest transaction rates require careful system design.
Real-time analytics architecture building blocks
Alex Bekker, head of the data analytics department at ScienceSoft, an international IT consulting and software development company, said the company uses the following blocks to structure IoT real-time analytics architectures:
things -- objects equipped with sensors to generate data for analysis;
gateways -- the linchpins between things and the cloud part of the architecture;
data lake -- a temporary reservoir to store data in its natural format;
big data warehouse -- a reservoir for storing processed and structured data to be further analyzed for meaningful insights;
data analysis segment -- where the analysis happens; and
control applications -- the blocks where automatic commands and alerts are sent to applications or real-world actuators in IoT apps.
Plan for growth of real-time analytics use cases
Once a few real-time analytics applications pan out, data managers and data engineers can be inundated with requests for new types of analytics.
"Once the business value of the analysis becomes clear, use of the system and richness of the analytics demanded may grow quickly," Riedel said.
He found that open standards and open frameworks can help solve key infrastructure scalability and adaptability challenges for both hardware and software. They also remove obstacles like vendor lock-in. This is important when data managers field requests for a sudden change in analysis approach or tooling that requires wholesale infrastructure change.
A common challenge Riedel sees lies in efficiently scaling analytics up when demand and analytics complexity increase and down when transactions or analysis is slowed. The applications can be easier to scale by pursuing open infrastructures, starting at the lowest levels.
Clarify objectives
Real-time analytics projects can get derailed when they take on too much streaming data or focus on the wrong objectives.
Mark Damm, founder and CTO of FuseForward Solutions Group Ltd., an AWS consulting partner, said many IT teams lack the skills, resources or budgets to handle large and complex data sets. As a result, only about 1% of the data generated is ever actually used.
Traditional, on-premises architectures are challenged to provide the appropriate storage, processing and quick response needed for streaming analytics.
Mark DammFounder and CTO, FuseForward Solutions Group Ltd.
He believes it is a mistake to start with the data architecture, infrastructure or tooling. Rather, it's much better to get as much clarity as possible on your organization's immediate and long-term objectives.
Next, identify the data streams that are available. Only then will it be feasible to make any information choices around infrastructure and tooling. Damm has found that deploying real-time analytics in the cloud can provide flexibility and agility to create and evolve new solutions quickly.
"Traditional, on-premises architectures are challenged to provide the appropriate storage, processing and quick response needed for streaming analytics," he said.
Damm sees fog computing as one increasingly popular way to handle complex data streaming for on-premises needs, since it makes it easier to move stream processing to the edge.
Reduce the noise in data processing
Understanding the business use case is one of most important elements in building infrastructure to support streaming, said Keith Kohl, senior vice president of product management at Information Builders, an analytics and data management tools provider. This can also make it easier to build applications that reflect business functions and are more modular and reusable.
Many popular stream processing tools include capabilities to filter out streaming data for particular functions. For example, the Kafka streaming data architecture lets you create topics with messages that are relevant for specific use cases. Analytics applications can be configured to subscribe to the appropriate subset of required topics. Other popular tools, like Apache Flink, Apache Spark and Apache Flume, have similar capabilities.
Streaming analytics components
As storage costs drop, it becomes more practical to save streaming data for subsequent analytics applications, said Ori Rafael, CEO of Upsolver, a data lake ingestion and transformation tool provider.
Enterprises are starting to adopt a streaming data architecture in which they store the data directly in the message broker, using capabilities like Kafka persistent storage or in data lakes using tools like Amazon Simple Storage Service or Azure Blob. These tools reduce the need to structure the data into tables upfront. However, data managers must spend more time structuring this data when new types of analytics are requested.
Another factor that can influence architectural choices are the types of queries required for different kinds of analytics, said Kiran Chitturi, CTO architect at Sungard AS, an enterprise backup tools provider. Some of the popular use cases include using distributed SQL engines, data warehouse storage or text search or sending low-latency streaming events to business apps.
It's also important to maintain the data provenance so that business users can understand what they're working with. Ed Cuoco, vice president of analytics at PTC, a lifecycle management software provider, said this can include understanding the data quality along with the volume from various sources. This can help business users determine the data suitability for various types of descriptive, diagnostic and predictive analytics.