data modeling
What is data modeling?
Data modeling is the process of creating a simplified visual diagram of a software system and the data elements it contains, using text and symbols to represent the data and how it flows. Data models provide a blueprint to businesses for designing a new database or reengineering a legacy application. Overall, data modeling helps an organization use its data effectively to meet business needs for information.
A data model can be thought of as a flow chart that illustrates data entities, their attributes and the relationships between entities. Its goal is to show the types of data in a system, its formats and attributes, relationships between data types and how they can be organized. Data modeling enables data management and data analytics teams to document data requirements for applications and identify errors in development plans before any code is written.
Data modeling is created using text, symbols and diagrams. It is typically built around business and application requirements, and additional feedback is gathered from end users and stakeholders. These are then translated into structures that create a database design. The data itself can be modeled at different levels of abstraction. Data models are also expected to change over time along with business needs.
Alternatively, data models can be created through reverse-engineering efforts that extract them from existing systems. That's done to document the structure of relational databases that were built on an ad hoc basis without upfront data modeling and to define schemas for sets of raw data stored in data lakes or NoSQL databases to support specific analytics applications.
Why is data modeling done?
Data modeling is a core data management discipline. By providing a visual representation of data sets and their business context, it helps pinpoint information needs for different business processes. It then specifies the characteristics of the data elements that are included in applications and in the database or file system structures used to process, store and manage the data.
Data modeling can also help establish common data definitions and internal data standards, often in connection with data governance programs. In addition, it plays a big role in data architecture processes that document data assets, map how data moves through IT systems and create a conceptual data management framework. Data models are a key data architecture component, along with data flow diagrams, architectural blueprints, a unified data vocabulary and other artifacts.
Traditionally, data models have been built by data modelers, data architects and other data management professionals with input from business analysts, executives and users. But data modeling is also now an important skill for data scientists and analysts involved in developing business intelligence (BI) applications and more complex data science and advanced analytics.
What are the different types of data models?
Data modelers use three types of models to separately represent business concepts and workflows; relevant data entities, their attributes and relationships; and technical structures for managing the data. The models typically are created in a progression as organizations plan new applications and databases. These are the different types of data models and what they include:
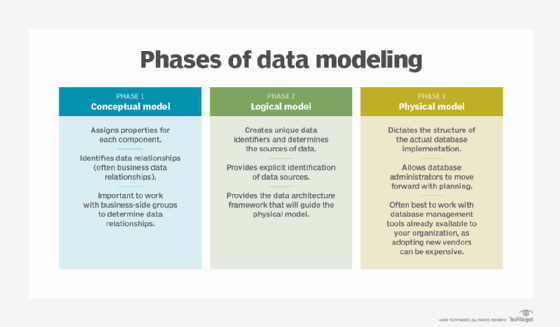
- Conceptual data model. This is a high-level visualization of the business or analytics processes that a system supports. It maps out the kinds of data that are needed, how different business entities interrelate and associated business rules. Business executives are the main audience for conceptual data models, which help them see how a system works and ensure that it meets business needs. Conceptual models aren't tied to specific databases or application technologies.
- Logical data model. Once a conceptual data model is finished, it can be used to create a less abstract logical one. Logical data models show how data entities are related and describe the data from a technical perspective. For example, they define data structures and provide details on attributes, keys, data types and other characteristics. Logical data models are used in specific projects, as they create a technical plot of data structures and rules.
- Physical data model. A logical model serves as the basis for the creation of a physical data model. It describes how data is stored in a physical database. Physical models are specific to the database management system (DBMS) or application software that will be implemented. They define the structures that the database or a file system use to store and manage the data. That includes tables, columns, fields, indexes, constraints, triggers and other DBMS elements. Database designers use physical data sources to create designs and generate schema for databases.
Logical and physical data models differ in that, while the logical data model characterizes data to an in-depth degree, the physical model acts as a step in creating a database.
Data modeling techniques
Data modeling emerged in the 1960s as databases became more widely used on mainframes and then minicomputers. It enabled organizations to bring consistency, repeatability and disciplined development to data processing and management. That's still the case, but the techniques used to create data models have evolved along with the development of new types of databases and computer systems.
These are the data modeling approaches used most widely over the years, including several that have largely been supplanted by newer techniques.
Hierarchical data modeling
Hierarchical data models organize data in a treelike arrangement of parent and child records. A child record can have only one parent, making this a one-to-many modeling method. The hierarchical approach originated in mainframe databases -- IBM's Information Management System (IMS) is one of the best-known examples. Although hierarchical data models were mostly superseded by relational ones beginning in the 1980s, IMS is still available and used by different organizations. A similar hierarchical method is also used today in Extensible Markup Language.
Network data modeling
This was also a popular data modeling option in mainframe databases that isn't used as much today. Network data models expanded on hierarchical ones by allowing child records to be connected to multiple parent records. This model enables node relationships to be connected in a many-to-many format. The Conference/Committee on Data Systems Languages (CODASYL), a now-defunct technical standards group, adopted a network data model specification in 1969. Because of that, the network technique is often referred to as the CODASYL model.
Relational data modeling
The relational data model was created as a more flexible alternative to hierarchical and network ones. First described in a 1970 technical paper by IBM researcher Edgar F. Codd, the relational model maps the relationships between data elements stored in different tables that contain sets of rows and columns, making it easy to identify data relationships and create entity relationship (ER) diagrams. Relational modeling set the stage for the development of relational databases, and their widespread use made it the dominant data modeling technique by the mid-1990s.
Entity relationship data modeling
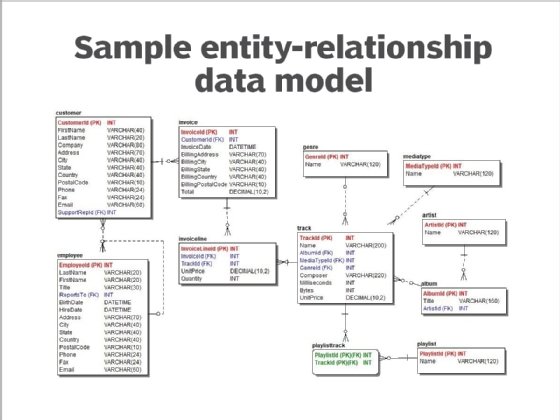
A variation of the relational model that can also be used with other types of databases, ER models visually map entities, their attributes and the relationships between different entities. For example, the attributes of an employee data entity could include last name, first name, years employed and other relevant data. ER models provide an efficient approach for data capture and update processes, making them particularly suitable for transaction processing applications.
Dimensional data modeling
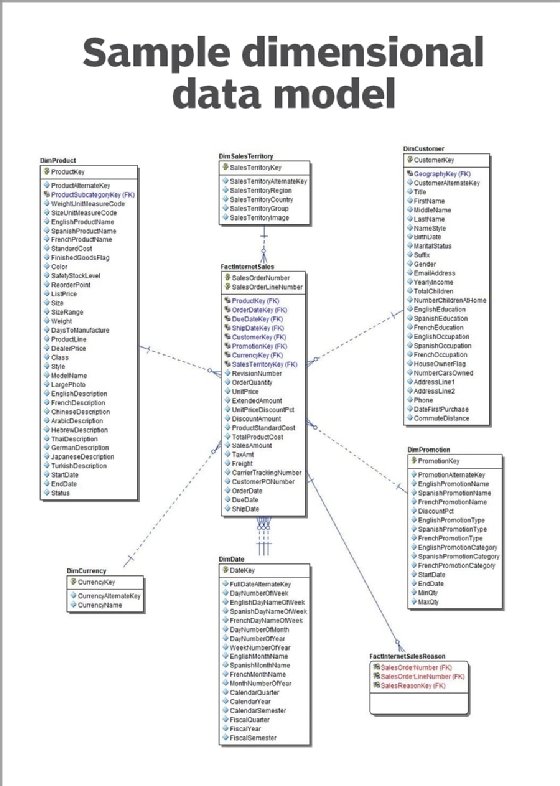
Dimensional data models are primarily used in data warehouses and data marts that support BI applications. They were designed to improve data retrieval speeds for analytics. Dimensional data models consist of fact tables that contain data about transactions or other events and dimension tables that list attributes of the entities in the fact tables. For example, a fact table could detail product purchases by customers, while connected dimension tables hold data about the products and customers. Notable types of dimensional models are the star schema, which connects a fact table to different dimension tables, and the snowflake schema, which includes multiple levels of dimension tables.
Object-oriented data modeling
As object-oriented programming advanced in the 1990s and software vendors developed object databases, object-oriented data modeling also emerged. The object-oriented approach is similar to the ER method in how it represents data, attributes and relationships, but it abstracts entities into objects. Different objects that have the same attributes and behaviors can be grouped into classes, and new classes can inherit the attributes and behaviors of existing ones. But object databases remain a niche technology for particular applications, which has limited the use of object-oriented modeling.
Graph data modeling
The graph data model is a more modern offshoot of network and hierarchical models. Typically paired with graph databases, it's often used to describe data sets that contain complex relationships. For example, graph data modeling is a popular approach in social networks, recommendation engines and fraud detection applications. Property graph data models are a common type -- in them, nodes that represent data entities and document their properties are connected by relationships, also known as edges or links, that define how different nodes are related to one another.
What is the data modeling process?
Ideally, conceptual, logical and physical data models are created in a sequential process that involves members of the data management team and business users. Input from business executives and workers is especially important during the conceptual and logical modeling phases. Otherwise, the data models may not fully capture the business context of data or meet an organization's information needs.
Typically, a data modeler or data architect initiates a modeling project by interviewing business stakeholders to gather requirements and details about business processes. Business analysts may also help design both the conceptual and logical models. At the end of the project, the physical data model is used to communicate specific technical requirements to database designers.
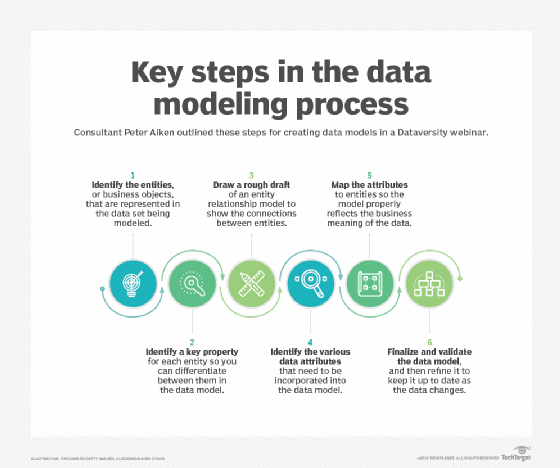
Peter Aiken, a data management consultant and associate professor of information systems at Virginia Commonwealth University, listed the following six steps for designing a data model during a 2019 Dataversity webinar:
- Identify the business entities that are represented in the data set.
- Identify key properties for each entity to differentiate between them.
- Create a draft ER model to show how entities are connected.
- Identify the data attributes that need to be incorporated into the model.
- Map the attributes to entities to illustrate the data's business meaning.
- Finalize the data model, and validate its accuracy.
Even after that, the process typically isn't finished. Data models often must be updated and revised as an organization's data assets and business needs change. This can be as often as weekly, monthly or over longer periods of time, like quarterly or annually.
How to choose a data modeling tool
BI tools commonly include data modeling software. However, it is still important to choose a tool that best suits both business and application needs. Important aspects to consider include the following:
- How well the tool facilitates collaboration between IT and business teams.
- Supported platforms and databases.
- Ease of use.
- Scalability.
- How many users can access the tool at once.
- What types of data modeling are supported by the tool.
Benefits and challenges of data modeling
Well-designed data models help an organization develop and implement a data strategy that takes full advantage of its data. Effective data modeling also helps ensure that individual databases and applications include the right data and are designed to meet business requirements for data processing and management.
Other benefits that data modeling provides include the following:
- Internal agreement on data definitions and standards. Data modeling supports efforts to standardize data definitions, terminology, concepts and formats enterprise-wide.
- Collaboration. The data modeling process provides a structure for IT and business teams to collaborate together, as both teams have to decide on data-related business and application requirements.
- Increased involvement in data management by business users. Because data modeling requires business input, it encourages data management teams and stakeholders to work together, which ideally results in better systems.
- More efficient database design at a lower cost. By giving database designers a detailed blueprint to work from, data modeling streamlines their work and reduces the risk of design missteps that require revisions later in the process.
- Better use of available data assets. Ultimately, good data modeling enables organizations to use their data more productively, which can lead to better business performance, new business opportunities and competitive advantages over rival companies.
- Data quality and error reduction. The data modeling process helps to identify any inconsistencies or errors in the software or data that improves overall data quality.
Data modeling is a complicated process that can be difficult to do successfully, however. These are some of the common challenges that can send data modeling projects off track:
- A lack of organizational commitment and business buy-in. If corporate and business executives aren't on board with the need for data modeling, it's hard to get the required level of business participation. That means data management teams must secure executive support upfront.
- A lack of understanding by business users. Even if business stakeholders are fully committed, data modeling is an abstract process that can be hard for people to grasp. To help avoid that, conceptual and logical data models should be based on business terminology and concepts.
- Modeling complexity and scope creep. Data models are often big and complex, and modeling projects can become unwieldy and inflexible if teams continue to create new iterations without finalizing the designs. It's important to set priorities and stick to an achievable project scope.
- Undefined or unclear business requirements. Particularly with new applications, the business side may not have fully formed information needs. Data modelers must often ask a series of questions to gather or clarify requirements and identify the necessary data.
Data modeling is one way an organization can focus in on and improve its data quality. Learn about other ways to improve data quality.






