
data mesh
What is a data mesh?
Data mesh is a decentralized data management architecture for analytics and data science. Traditional data architectures often centralize data, leading to challenges in scalability, flexibility and governance. Data mesh proposes a decentralized approach where data is treated as a product and managed by decentralized teams or domains within an organization, such as marketing, sales and customer service.
The term was coined by Zhamak Dehghani in 2019 while at the consultancy Thoughtworks to help address some of the fundamental shortcomings in traditional centralized architectures such as data warehouses and data lakes.
Why use a data mesh?
Data mesh is an emerging concept in data architecture that offers several benefits for organizations. Here are some key reasons why organizations might consider using data mesh:
- Decentralized data ownership. By distributing data ownership among domain-specific teams, data mesh aids democratization, removes bottlenecks and empowers teams to make decisions about their data. This leads to faster innovation and better alignment with business objectives.
- Improved data access and scalability. A data mesh improves the experience and efficiency of the teams consuming the data by enhancing data access, security and scalability. Its goal is to increase the accessibility and availability of data to business users by establishing direct connections between data owners, producers and consumers. This ultimately enhances the effectiveness of data-centric options, allows for faster decision-making and encourages the adoption of modern data architectures.
- Cost efficiency. Distributed data mesh architectures typically shift away from batch processing. Instead, they lean toward the adoption of real-time data streaming and cloud services. This transition enhances visibility into resource allocation and storage costs, thereby refining budgeting practices and lowering overall expenses. It also lowers the costs of setting up new analytics and data science products.
- Data quality and governance. Centralized architectures may struggle to maintain data quality and enforce governance standards, as these responsibilities are often centralized within the data team. Data mesh encourages domain-specific teams to take ownership of their data, which leads to better data quality and compliance with governance standards.
- Data silos and disaster recovery. One significant advantage of data mesh lies in its capacity to diminish data silos. Through the deployment of a self-service data infrastructure, data becomes easily accessible across domains, promoting collaboration and accelerating the pace of data discovery.
- Artificial intelligence (AI) and machine learning (ML). The decentralization of data within a data mesh architecture is conducive to deploying AI and ML options, which frequently rely on extensive and diverse data sets to operate efficiently. With easier access to data and resources, teams can iterate more quickly on AI and ML experiments and prototypes, which helps with refining models and improving their performance over time.
- Reduces technical debt. Data mesh reduces technical debt that is usually caused by a centralized data infrastructure. It enables users to prioritize tasks that better utilize their skill sets, addresses duplication of efforts and distributes the data pipeline by domain ownership, thus reducing technical strains on the storage system.
How does data mesh work?
Previously, a centralized infrastructure team would manage data ownership across domains. However, a data mesh model shifts this ownership to the producers as they are the subject matter experts in the field. They can design APIs with the interests of the main data consumers in mind because they have a solid understanding of how they use the operational and analytical data in the domain.
In addition to placing responsibility for cataloging information, establishing policies for usage and permissions and defining semantic definitions, this domain-driven approach also maintains a centralized data governance team to enforce these standards and practices surrounding the data.

Core principles of data mesh architecture
Dehghani advocates four core principles that underlie data mesh architecture for data analytics and data science applications.
1. Domain-oriented data ownership and architecture
A data mesh builds on author Eric Evans' theory of domain-driven design that explores how to deconstruct applications into distributed services aligned around business capabilities. Data ownership is distributed among different teams or domains, each responsible for managing their extract, transform and load (ETL) pipelines and sharing data related to their domain expertise.
But instead of thinking only about services, data teams also need to host and serve domain data sets in a way that's easily consumed by others across the organization. Rather than push and ingest data, these teams need to think about how to host data that different users can pull.
The core principle is that data should be the responsibility of the business teams closest to the data. Domain teams should have access to tools that create analytics data, its metadata and all the computations required to serve it.
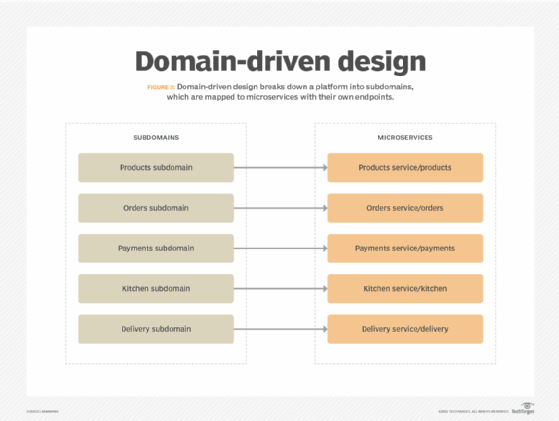
2. Data as a product
The software industry has been transitioning from project management to product management. A data mesh applies the same concept to data products. Domain experts must focus on improving various aspects of these data products, such as data quality, lead time of data consumption and user satisfaction.
Data products must be the following to be successful:
- Discoverable. Every data product logs its information into a centralized data catalog to facilitate effortless delivery.
- Addressable. Each data product needs a unique address, enabling data consumers to access them programmatically. Typically, these addresses adhere to organization-wide naming standards that are set centrally.
- Reliable. When a team depends on a data product, they should feel secure that it won't break or alter unexpectedly and disrupt their workflows. Additionally, people should have the assurance that the underlying data is reliable.
- Self-serving. Data products should be simple for teams to access and use, ideally in a self-service style such as a self-service business intelligence report.
A fundamental principle is that accountability shifts as close to the data source as possible rather than to a data engineering team that may be less familiar with how the data was collected, what it means and how it might be used. Data engineering teams need to focus on setting up the infrastructure that works across business domains so it's easier to create and manage these products through capabilities such as discoverability, explorability, security, trustworthiness and understandability.
A data product is built on several structural components, including the following:
- The code supports the data pipelines, APIs that access the data and access control policies.
- The data can consist of events, tables, batch files or graphs, while the metadata describes what it means.
- The infrastructure helps physically provision and manage the data.
3. Self-service data platform
Business teams aren't data engineers or data scientists, nor should they be. Data engineers must build the appropriate infrastructure to provide these domain experts with domain autonomy. This infrastructure might take advantage of existing data platforms and tools, but it also needs to support self-service provisioning capabilities for data products that are accessible to a broader audience. These users should be able to work with data storage formats, create data product schemas, set up data pipelines, manage data product lineage and automate governance.
One approach is to set up a multiplane data platform analogous to the different planes in network routing. A data infrastructure provisioning plane helps set up the underlying infrastructure. A data product developer experience plane simplifies development workflows with tools to create, read, version, secure and build data products. A data mesh supervision plane helps execute new services across the infrastructure for things including discovering data products or correlating multiple data products together.
4. Federated computational governance
A data mesh needs a decentralized governance model that can automate the execution of decisions across the platform. This model ensures interoperability across the different data sources. It can also help correlate, join and perform other operations across multiple data products at scale.
That differs from traditional data governance approaches for analytics that try to centralize all decision-making. Each domain is responsible for some decisions, such as the domain data model and quality assurance. A centralized data engineering team shifts its focus to automating many aspects of governance, such as setting up tools to detect and recover from errors, automate processes and establish service-level objectives for the enterprise.
Data mesh vs. data lake
The main difference between a data lake and a data mesh lies in their architectural approaches and organizational principles for managing data.

Data lake
- A data lake is a repository where both structured and unstructured data are stored and processed.
- A data lake centralizes all data to improve reuse across the organization.
- Large volumes of diverse data are collected in data lakes for various analytics and processing purposes.
- The focus is on improving the infrastructure for ingesting data and then transforming it after it has been stored.
- Concerns about data quality and transformation are applied after the fact by data engineering teams that might not be familiar with how the data was collected and what it means.
Data mesh
- A data mesh is a set of organizational principles highlighting decentralized teams, federated governance, the treatment of data as a product and the facilitation of self-service data access.
- Data mesh is a transition away from monolithic structures and toward flexibility, scalability and accessibility, similar to the advent of microservices for software engineering.
- A data mesh engages domain experts to clean up data as it enters the system. As with DevOps in software development, this process identifies defects much earlier in the data lifecycle, where it's cheaper and easier to remediate.
- In a data mesh, data engineering teams focus on the infrastructure to enable data domain experts to create their own data products with self-service access.
Data mesh vs. data fabric
Data mesh and data fabric are both approaches to managing and using data within organizations, but they differ in their architectural focus and execution.
Data fabric
- Data fabric mainly focuses on centralization, automated and unified data access.
- A data fabric is a modern design concept that uses machine learning, technical analysis and semantic data to support the design, deployment and use of data infrastructure.
- Technologies such as semantic knowledge graphs, active metadata management and machine learning help monitor and tune data infrastructure.
- Data fabrics attempt to automate tasks such as discovering and aligning schemas, healing data pipeline failures and profiling data.
- Data fabric optimizes the data lifecycle and accelerates the development of data-driven applications in real time by integrating data from various sources.
Data mesh
- A data mesh architecture shifts the focus from a centralized data infrastructure to autonomous and domain-specific data products.
- It is designed to promote collaboration and aims to minimize barriers to accessing data.
- Data engineering teams are required to develop a platform for empowering federated business teams to manage more aspects of data quality on their own.
- A data mesh may take advantage of data fabrics to help set up a self-service data infrastructure platform along with other data management applications and platforms.
Data mesh design challenges
With its numerous benefits and use cases, data mesh can also present several challenges in its design and execution. Some challenges with data mesh design include the following:
- Complicated setup. Setting up and maintaining a data mesh infrastructure might be challenging, particularly if the team assigned to the task is unfamiliar with the underlying architecture.
- Requires customization. There is no one-size-fits-all when it comes to data mesh architecture, as it must be tailored to fit the unique needs of each organization.
- Time investment. Setting up data meshes may demand substantial investments in terms of time, resources and expertise.
- Complex management. Operating and maintaining data meshes, particularly at scale, can prove intricate. It's a balancing act between modularity and simplicity.
- Difficult to modify. Once established, data meshes can be challenging to modify or adjust. Therefore, it's important to get them right initially.
- Data silos. Data meshes have the potential to create data silos that are hard to dismantle, possibly leading to duplicated efforts.
Best practices for data mesh design and execution
Some best practices for designing and executing data meshes include the following:
- Domain-oriented data ownership. The domain teams should be encouraged to take ownership of their data to treat it as a product. This is important because domain teams possess deep knowledge and expertise about the data within their specific area. By assigning ownership to these teams, organizations employ their subject matter expertise to better understand, manage and utilize the data.
- Look into change management. Enterprises need to approach data mesh design as an organizational problem. The biggest challenge is change management. Business units that generate their data might not be familiar with how to create data products. Data domain experts need to learn about concepts such as data quality, service-level objectives and experience design for data users. Business units may perceive this shift as an additional burden. Business teams might also lack a culture of data literacy that understands how to communicate data requirements and suitability for different use cases.
- Start with a small project. It's probably best to start with a small project to create a set of data products that are critical to different areas of the business. These teams should identify essential data requirements for existing use cases and then collaborate on the first data product prototype. Over time, they can refine these requirements and establish best practices to ensure high quality and improve the data consumption experience.
- Data literacy and expertise. It might also be helpful to bring in application product experts to help guide these discussions. Enterprises might also want to introduce data literacy across the organization to help identify ways to use these early data products. Once a baseline is established, data engineering teams can shortlist the kind of self-service infrastructure that might help automate the process of creating and sharing data products.
- Adoption of serverless technologies for agility. The adoption of serverless and containerized cloud-native technologies can greatly improve data management agility. This is because serverless computing and containerization enable automatic scaling of resources based on demand. This ensures that data processing and analytics tasks can scale seamlessly to handle varying workloads, improving agility in responding to changing data processing needs.
Explore the decentralized approach of data mesh compared to traditional options such as data warehouses, data lakes and data fabrics. Learn how data mesh increases data access and unlocks greater value from data.
Continue Reading About data mesh
Dig Deeper on Data management strategies
-
![]()
Data contracts help build trustworthy data products for AI
By: Stephen Catanzano
-
![]()
Key considerations for data-intensive architectures
By: Priyank Gupta
-
![]()
Qlik's Mozaic acquisition adds decentralized data management
By: Eric Avidon
-
![]()
Starburst update adds new GenAI, streaming data features
By: Eric Avidon



