What is a vector database?

A vector database is a type of database technology that's used to store, manage and search vector embeddings, numerical representations of unstructured data that are also referred to simply as vectors. Long a niche technology, vector databases are now being used more widely to support artificial intelligence (AI) and machine learning applications, including generative AI (GenAI) ones.
Rather than storing unstructured data objects as text, images or video and audio files, a vector database stores them as a series of numbers plotted in a multidimensional space. The basic idea behind using high-dimensional vectors is that the assigned numbers can represent the semantic meaning of different data points in a more precise way than using conventional text-based metadata to describe the data.
Vector databases are optimized to enable users or applications to effectively find and retrieve relevant data through vector search techniques that match data points based on their similarity or how closely they're plotted. As a result, the search function is also known as vector similarity search.
There are multiple forms of vector database technologies. Among them are purpose-built vector databases that only support vector storage and are sometimes called native vector databases. Support for vectors and vector search has also become increasingly common in multimodel databases that are designed to be used with different data models.
Why are vector databases important?
Vector databases were first developed as a distinct product category in the early 2000s, but interest in them is surging alongside the increasing adoption of AI and machine learning technologies. They're important to organizations for the following reasons:
- Enabling semantic search and similarity matching. With a traditional database, searches are often executed as a keyword match function. Vector databases let users search and match data based on its meaning and context. This enables highly accurate associations that can be used to help power multiple use cases that aren't well served by other kinds of databases.
- Supporting multimodal applications. As opposed to struggling to manage different data types, a vector database stores and retrieves data across multiple modalities in the same fashion. Text, images, video, audio and more are all represented as vectors in the same multidimensional embedding space, also sometimes called a vector space. This enables multimodal applications, such as multimedia search and data retrieval across different types of data.
- Enhancing generative AI applications. Perhaps the biggest reason why vector databases are now more important than in the past is the rapid growth of the large language models (LLMs) that power ChatGPT, Gemini, Microsoft Copilot and other GenAI tools. The databases are a key component in various GenAI applications. For example, a vector database can serve as a knowledge store for updated information that an LLM can access to improve the accuracy of GenAI responses, an approach known as retrieval-augmented generation (RAG).
What are vector embeddings?
Vector embeddings are the data type stored in a vector database. The numerical representations in a vector embedding are intended to capture the meaning of a data point and its relationship to other data entities, such as the words in a sentence or different phrases.
A vector embedding converts data points into an array of numbers across multiple dimensions. Each dimension represents a specific feature or attribute that captures some aspect of the data's meaning or context. Similarity metrics are then used to position data points in an embedding space when searches are run in a vector database. Data points with similar attributes are placed closer together than ones that differ more from each other.
How do vector databases work?
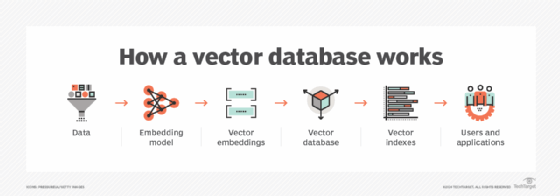
Vector databases provide mechanisms for users to ingest, store and manage vector embeddings and then run searches on the embeddings to find similar or relevant data. Here's a step-by-step explanation of how the databases work:
- Data ingestion and vectorization. The first step is to ingest the raw data and convert it into vector embeddings. The latter task is done by feeding the data into an embedding model, a type of neural network that uses machine learning and deep learning algorithms to generate the vector embeddings. After being trained on a data set, an embedding model analyzes it to identify the patterns and relationships that form the basis of the numerical representations in embeddings.
- Vector storage. The vector embeddings, or vectors, are stored in the database system in an optimized format to support the planned applications.
- Vector indexing. To support efficient vector search, the stored embeddings are indexed using a variety of techniques designed to enable the database to quickly find vectors that are similar to the query vector in a search. Common indexing approaches include Hierarchical Navigable Small World (HNSW) graphs that organize vectors into multilayer graph structures based on their proximity to one another; product quantization (PQ), which compresses high-dimensional vectors to reduce memory requirements and boost search performance; and locality-sensitive hashing (LSH), a technique that uses hash functions to bucket similar vectors together.
- Vector search. When a user or application submits a database query for a similarity search, it's converted into a vector representation. In many cases, an approximate nearest neighbor (ANN) algorithm is used to find data points that are close to the query vector, which trades off some accuracy for fast search performance. HNSW, PQ and LSH indexing all support ANN searches. For more accurate and precise search results, some vector databases also support the use of K-nearest neighbor (KNN) algorithms to find a specific number of vectors that are closest to the query vector. With both ANN and KNN algorithms, the similarity between vectors is based on a distance metric, such as cosine similarity, Euclidean distance or dot product.
- Data retrieval. After the search is complete, the vector database will retrieve the original data stored in it that's associated with the vectors returned by the similarity search. This step might also include post-processing measures, such as applying a different similarity metric to rank the nearest-neighbor data points in another way.
Vector databases vs. traditional databases
Various types of databases are available to deploy. Traditional database technologies include relational databases, which store data in row-based tables and are the most widely used database software overall because they're well suited to transaction processing applications. NoSQL databases that emerged starting in the mid-2000s are also commonly used in various applications. Four separate product categories are included under the NoSQL technology umbrella: key-value databases, document databases, wide-column stores and graph databases.
While many relational and NoSQL database management systems now offer multimodel support, including the ability to store vector data in some cases, that's accomplished through separate product modules for the individual technologies. The following table outlines some of the primary differences between vector, relational and NoSQL databases.
| Vector databases | Relational databases | NoSQL databases | |
| Data storage | Store data as high-dimensional vector embeddings. | Store data in tables with rows and columns. | Store data in various formats, such as documents, key-value pairs and graphs. |
| Data types | Optimized for unstructured data, such as text, images, audio and video. | Designed for transactions and other forms of structured data. | Typically can handle structured, semistructured and unstructured data. |
| Querying | Use similarity search based on distance and proximity metrics between vectors. | Use SQL queries based on exact matches and conditions. | Supported query languages vary based on the database and data model. |
| Indexing | Use specialized vector indexing techniques for efficient similarity search performance. | Use B-tree, hash, clustered, nonclustered and other index types. | Use various indexing techniques depending on the database and data model. |
| Schema | Schemaless, flexible data model. | Fixed schema for data consistency. | Schemaless or flexible schema in most cases. |
Like other database technologies, vector databases can be deployed both in the cloud and in on-premises data centers. With cloud deployments, user organizations have a choice of self-managed database systems or managed services offered by database vendors under two models: serverless databases and database as a service, or DBaaS.
What are some applications and use cases for vector databases?
Vector databases are considered a special-purpose database technology. Nonetheless, they're well suited to numerous applications and use cases, including the following:
- Generative AI. As mentioned above, vector database technology is a key component in GenAI development that's widely used to support LLMs and RAG deployments.
- Recommendation systems. Vector databases are also commonly used to power recommendation engines, including ones that suggest related products and content to customers.
- Anomaly detection. Different types of anomaly detection applications, such as fraud detection, network security monitoring and manufacturing quality control, are supported by vector databases.
- Computer vision. The similarity search functionality of a vector database is often used to help enable image retrieval, facial recognition, object detection and image classification.
- Natural language processing. Vector search plays a central role in natural language processing applications in various domains, including chatbots, virtual assistants and conversational AI technologies.
- Bioinformatics and life sciences tasks. The ability to accurately identify related items with a vector database is critical for uses such as protein structure comparison, gene sequence matching and drug discovery.
What are the benefits of using a vector database?
Vector databases can help organizations and their application developers and end users in various ways. The following are among the benefits that vector databases provide:
- More efficient similarity search. Used effectively, a vector database enables fast and accurate retrieval of semantically similar data points to help boost application performance.
- An alternative to keyword-based search. A vector database can also help improve relevance and accuracy on queries of unstructured data by enabling more nuanced and context-aware search results than conventional keyword matching.
- Optimized for high-dimensional data. Being able to map data points across hundreds or thousands of dimensions enables users to run highly granular searches focused on specific features and attributes in a data set.
- Integration with generative AI models. A vector database serves as an external knowledge base for GenAI applications, which can help reduce AI hallucinations that produce false information.
- Simplified data indexing. Support for specialized indexing techniques such as HNSW, PQ and LSH can make it easier for users to create indexes.
- Built-in data management and security features. A vector database provides data storage and management capabilities that aren't available in alternative technologies, such as vector search libraries or standalone vector indexes.
What challenges do vector databases pose?
The following are some common challenges that organizations face on vector database deployments:
- Cost considerations. Storage and compute requirements can result in high hardware costs, especially if GPUs -- graphics processing units -- are needed to run AI applications instead of conventional processors.
- Deployment complexity. Vector database setup and maintenance might be challenging for data management teams that don't have the right experience and skills.
- Scalability demands. As data volumes and vector dimensions grow, the system resources needed for scalable search and data retrieval performance can increase substantially, adding more cost and complexity to a vector database implementation.
- Data integrity and consistency. Ensuring high levels of data quality and consistency across vector embeddings can be complicated.
- Query accuracy vs. performance. There's a need to balance query speed with accuracy and precision in vector search results, which can be difficult to get right.
- Integration with existing systems. Adapting applications already in use to work with vector databases potentially requires significant updates to data infrastructure and application logic.
- Versioning. Managing different versions of vector embeddings as AI models or data sets evolve is a nontrivial task.
Continue Reading About What is a vector database?
Dig Deeper on Database management
-
![]()
Teradata updates vector indexing suite to aid AI development
By: Eric Avidon
-
![]()
ScyllaDB adds vector search to managed database platform
By: Eric Avidon
-
![]()
Different types of database management systems explained
By: Craig Mullins
-
![]()
AWS data & analytics VP: Charting new oceans, the evolution of data lakes
By: Adrian Bridgwater



