Google Bigtable

What is Google Bigtable?
Google Bigtable is a distributed NoSQL database service created by Google to handle large amounts of structured, semistructured and unstructured data. Although Bigtable is available as a public subscription service, the platform also supports many of Google's own core services, including Google Search, Google Maps, Google Drive, Google Analytics and YouTube.
Bigtable was designed to support analytical and operational workloads requiring massive scalability. The platform can scale to petabytes of data, with workloads spread across thousands of commodity servers. The platform can also deliver single-digit millisecond latency and promises up to 99.999% high availability. Bigtable is based on a sparsely populated table design that can accommodate thousands of columns and billions of rows.
Bigtable is capable of processing more than 6 billion requests per second. Customers can seamlessly scale their operations from thousands to millions of read/write operations per second by adding or removing cluster nodes, and they can make these changes without incurring downtime. They can also automatically scale their clusters up or down to meet fluctuating workload demands. In addition, Bigtable supports automatic replication with eventual consistency.
According to Google, the Bigtable service can accommodate multiple types of data, making it possible to support a variety of workloads. This includes financial data, marketing data, graph data, time-series data and IoT data. The platform is well-suited to batch MapReduce operations, machine learning applications, and stream processing and analytics. The Bigtable service currently manages over 10 exabytes of data.
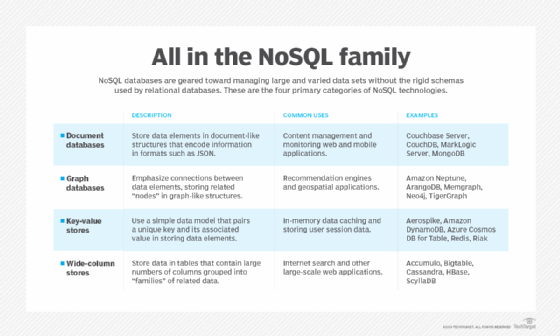
How is data stored in Bigtable?
Bigtable stores data in scalable tables made up of columns and rows. Each table provides a sorted key/value map, with each row indexed by a single row key. Related columns are often grouped into column families and a unique name is assigned to each column family. The tables are also sparse; if a column does not contain data for a particular row, the cell does not use any storage space.
Within these tables, each row/column intersection can contain one or more cells. In a traditional relationship database table, each row/column intersection can contain only one cell. Every cell in a Bigtable table contains a unique timestamped version of the data. This approach enables Bigtable to maintain a record of how data has changed over time.
The tables in a Bigtable database are sharded into blocks of contiguous rows that are referred to as tablets. Tablets are flexible structures that make it easier to balance workloads across server nodes. The tablets are stored in the SSTable format on Google's Colossus file system. An SSTable is a file that contains sorted key-value pairs. The file provides a key-to-value mapping that is ordered, persistent and immutable. Both the keys and values are arbitrary byte strings.
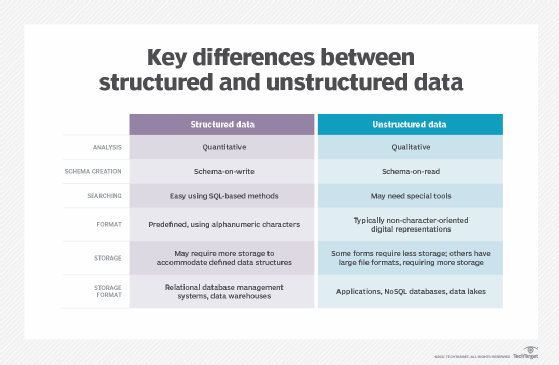
The Bigtable service is organized into a hierarchy of components made up of instances, clusters and nodes. These components provide customers with an overall structure for working with their databases:
- Instance. The instance sits at the top of the hierarchy. It offers a logical structure for deploying a Bigtable database, while providing a container for the customer's data. An instance requires more than one cluster to support replication. The storage type (SSD or HDD) is determined at the instance level.
- Cluster. An instance contains one or more clusters. Each cluster is located in a specific zone. Google organizes its data services into regions, which contain individual zones. A single Bigtable instance can contain clusters in up to eight regions; however, each zone can include only one cluster.
- Node. A cluster contains one or more nodes. The nodes provide the compute resources necessary to drive the Bigtable operations. A tablet is associated with a specific node at any given time. The node tracks the tablets that are assigned to that node. A node never stores the data, only points to it. In this way, Bigtable can quickly rebalance nodes by updating the pointers. It can also seamlessly recover from node failure without losing data. In addition, the nodes handle incoming read/write requests for the tablets and perform maintenance tasks on them, such as compacting the data.
All client requests to the Bigtable service go through a front-end server pool, which forwards the requests to the individual Bigtable nodes. The nodes then communicate with their respective tablets. By adding nodes to a cluster, customers can increase the number of simultaneous requests that their clusters can handle, while also increasing the cluster's maximum throughput.
Google has maintained Bigtable as a proprietary, in-house technology. Nevertheless, Bigtable has had a large impact on NoSQL database design. In 2006, Google software developers publicly disclosed Bigtable details in a technical paper presented at the USENIX Symposium on Operating Systems and Design Implementation.
The paper's thorough description of Bigtable's inner workings allowed other organizations and open source development teams to create database systems that are modeled after Bigtable. Those systems include Apache HBase database, which runs on top of the Hadoop Distributed File System (HDFS); Cassandra, which originated at Facebook; and Hypertable, an open source project that ended development in 2016.
Explore 7 Google Cloud database options to free up your IT team. See also: columnar database and check out 18 top big data tools and technologies to know about.
Continue Reading About Google Bigtable
Dig Deeper on Database management
-
![]()
Google Data Engineer Certification Exam Dumps and Braindumps
By: Cameron McKenzie
-
![]()
Certified GCP Data Engineer Sample Questions and Answers
By: Cameron McKenzie
-
![]()
Google Cloud Data Engineer Practice Exam Questions
By: Cameron McKenzie
-
![]()
Braindumps and Exam Dumps for Google's Certified Professional Database Engineer Test
By: Cameron McKenzie



