Inline deduplication fits well with hyper-converged IT
Of the two main types of deduplication, most HCI vendors choose inline over post-process because of the performance benefits and lower levels of total storage required.
Inline deduplication is rapidly becoming a standard feature in hyper-converged appliances.
The deduplication of data helps a hyper-converged appliance use its internal storage more efficiently. Performing deduplication inline also helps to avoid wear and performance issues that are commonly associated with post-process deduplication.
One of the things that sets hyper-converged infrastructure (HCI) apart from other computing platforms is that hyper-converged systems are designed to be fully integrated systems. A hyper-converged appliance typically contains its own compute, storage and hypervisor resources.
While there are considerable advantages to an appliance using local storage resources, there is also at least one disadvantage. Because there is a limit to the number of disks that a hyper-converged appliance can physically accommodate, there will always be a finite amount of storage available to workloads running on hyper-converged systems. Storage resources must therefore be used efficiently so as to avoid depletion. One of the best options for conserving disk space is to eliminate the storage of redundant data through the use of storage deduplication.
Deduplication options
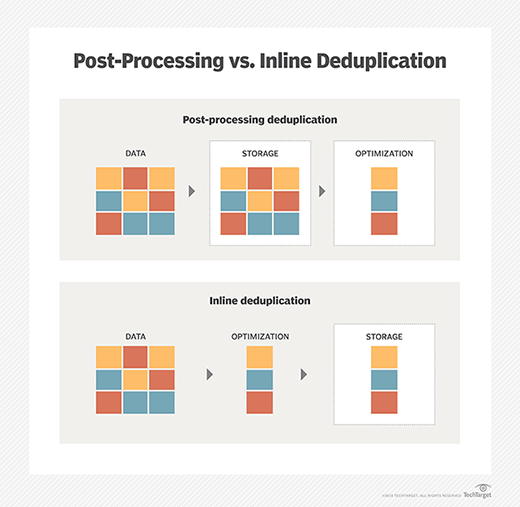
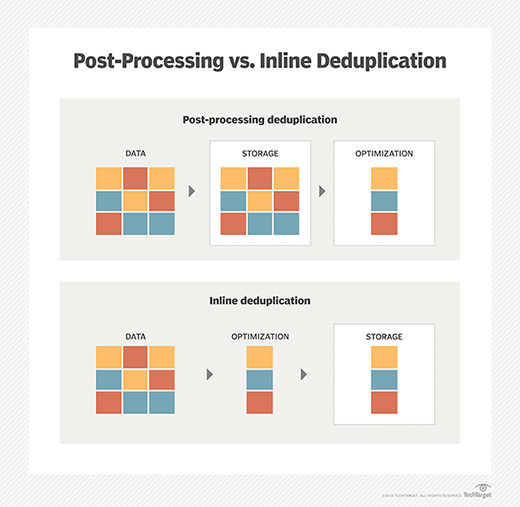
Deduplication is usually classified as being either inline or post-process, although there are hybrid deduplication methods, blending the two types. Inline deduplication eliminates redundant data in real time, before that redundant data can be written to disk.
The most typical method of inline deduplication uses hash identifiers that are appended to data before it gets stored. Deduplication software checks data ready to be sent to storage against the hashes in stored data. Any data with matching hashes doesn't get sent to storage.
Conversely, post-process deduplication allows all inbound data to be written to disk but uses a scheduled process to identify and remove redundant data at a later time. The same algorithmic process based on identifier hashes happens with post-process deduplication, but after the batch of data gets stored. Any data with matching hashes gets deleted.
Why post-process may not be right for HCI
Both inline and post-process deduplication will eliminate redundant data, helping storage to be used more efficiently. When it comes to hyper-converged appliances, however, inline deduplication is likely to be the better option.
There are two main reasons why post-process deduplication may not be the best choice for use in HCI appliances. First, post-process deduplication occurs after the redundant data has already been written to the appliance's storage. This means that the benefits of deduplication are not immediately realized, because the appliance must initially store the data in its nondeduplicated state and must therefore have sufficient capacity to accommodate the extra data.
Depending on the server's workload and when the deduplication process is scheduled to run, post-process deduplication can negatively affect the appliance's performance.
A second reason why post-process deduplication may not be the best fit for hyper-converged appliances has to do with the way that many such appliances store data.
Hyper-converged appliances commonly make use of two storage tiers. Such appliances are equipped with a high-speed tier made up of flash storage and a high-capacity tier based on spinning media.
The high-speed storage tier serves two main purposes. First, this tier acts as a read cache. Hot data -- data that has been accessed recently -- is automatically moved to the high-speed tier so that it can be read more quickly than would be possible if the data were being accessed from the high-capacity tier.
The high-speed storage tier also sometimes acts as a write buffer. Newly created data is written to the high-speed tier and then is later automatically moved to the high-capacity tier. This approach helps to keep write operations from causing an I/O bottleneck.
Using flash media as a write cache means that each write operation results in a program-erase cycle. If deduplication is being performed in post-process, then it could mean that redundant data is being written to flash storage -- assuming that flash is being used for the landing zone -- only to be erased later on. This process shortens the life of the appliance's flash media. If, on the other hand, inline deduplication is used, then the data will be deduplicated before it is ever written to the device's storage.
The other thing to consider is that post-process deduplication is an I/O-intensive process. Depending on the server's workload and when the deduplication process is scheduled to run, post-process deduplication can negatively affect the appliance's performance. Again, this is not an issue with inline deduplication.








{kind=link}