data compression
What is data compression?
Data compression is a reduction in the number of bits needed to represent data. Compressing data can save storage capacity, speed up file transfer and decrease costs for storage hardware and network bandwidth.
How compression works
Compression is performed by a program that uses a formula or algorithm to determine how to shrink the size of the data. For instance, an algorithm may represent a string of bits -- or 0s and 1s -- with a smaller string of 0s and 1s by using a dictionary for the conversion between them. The formula may also insert a reference or pointer to a string of 0s and 1s that the program has already seen.
Text compression can be as simple as removing all unneeded characters, inserting a single repeat character to indicate a string of repeated characters and substituting a smaller bit string for a frequently occurring bit string. Data compression can reduce a text file to 50% or a significantly higher percentage of its original size.
For data transmission, compression can be performed on the data content or on the entire transmission unit, including header data. When information is sent or received via the internet, larger files -- either singly or with others as part of an archive file -- may be transmitted in a ZIP, GZIP or other compressed format.
Why is data compression important?
Data compression can dramatically decrease the amount of storage a file takes up. For example, in a 2:1 compression ratio, a 20 megabyte (MB) file takes up 10 MB of space. As a result of compression, administrators spend less money and less time on storage.
Compression optimizes backup storage performance and has recently shown up in primary storage data reduction. Compression will be an important method of data reduction as data continues to grow exponentially.
Virtually any type of file can be compressed, but it's important to follow best practices when choosing which ones to compress. For example, some files may already come compressed, so compressing those files would not have a significant impact.
Data compression methods: lossless and lossy compression
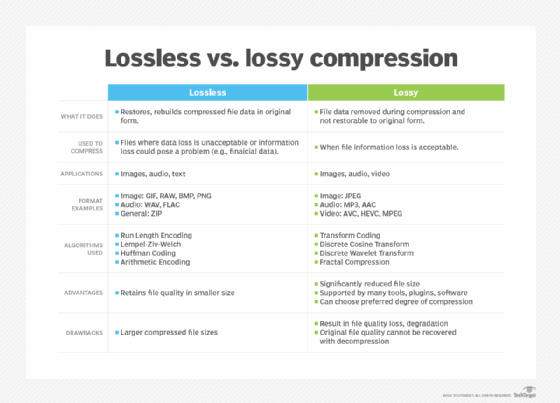
Compressing data can be a lossless or lossy process. Lossless compression enables the restoration of a file to its original state, without the loss of a single bit of data, when the file is uncompressed. Lossless compression is the typical approach with executables, as well as text and spreadsheet files, where the loss of words or numbers would change the information.
Lossy compression permanently eliminates bits of data that are redundant, unimportant or imperceptible. Lossy compression is useful with graphics, audio, video and images, where the removal of some data bits has little or no discernible effect on the representation of the content.
Graphics image compression can be lossy or lossless. Graphic image file formats are typically designed to compress information since the files tend to be large. JPEG is an image file format that supports lossy image compression. Formats such as GIF and PNG use lossless compression.
Compression vs. data deduplication
Compression is often compared to data deduplication, but the two techniques operate differently. Deduplication is a type of compression that looks for redundant chunks of data across a storage or file system and then replaces each duplicate chunk with a pointer to the original. Data compression algorithms reduce the size of the bit strings in a data stream that is far smaller in scope and generally remembers no more than the last megabyte or less of data.
File-level deduplication eliminates redundant files and replaces them with stubs pointing to the original file. Block-level deduplication identifies duplicate data at the subfile level. The system saves unique instances of each block, uses a hash algorithm to process them and generates a unique identifier to store them in an index. Deduplication typically looks for larger chunks of duplicate data than compression, and systems can deduplicate using a fixed or variable-sized chunk.
Deduplication is most effective in environments that have a high degree of redundant data, such as virtual desktop infrastructure or storage backup systems. Data compression tends to be more effective than deduplication in reducing the size of unique information, such as images, audio, videos, databases and executable files. Many storage systems support both compression and deduplication.
Data compression and backup
Compression is often used for data that's not accessed much, as the process can be intensive and slow down systems. Administrators, though, can seamlessly integrate compression in their backup systems.
Backup is a redundant type of workload, as the process captures the same files frequently. An organization that performs full backups will often have close to the same data from backup to backup.
There are major benefits to compressing data prior to backup:
- Data takes up less space, as a compression ratio can reach 100:1, but between 2:1 and 5:1 is common.
- If compression is done in a server prior to transmission, the time needed to transmit the data and the total network bandwidth are drastically reduced.
- On tape, the compressed, smaller file system image can be scanned faster to reach a particular file, reducing restore latency.
- Compression is supported by backup software and tape libraries, so there is a choice of data compression techniques.
Pros and cons of compression
The main advantages of compression are a reduction in storage hardware, data transmission time and communication bandwidth -- and the resulting cost savings. A compressed file requires less storage capacity than an uncompressed file, and the use of compression can lead to a significant decrease in expenses for disk and/or solid-state drives. A compressed file also requires less time for transfer, and it consumes less network bandwidth than an uncompressed file.
The main disadvantage is the performance impact from the use of CPU and memory resources to compress the data. Many vendors have designed their systems to try to minimize the impact of the processor-intensive calculations associated with compression. If the compression runs inline, before the data is written to disk, the system may offload compression to preserve system resources. For instance, IBM uses a separate hardware acceleration card to handle compression with some of its enterprise storage systems.
If data is compressed after it is written to disk, or post-process, the compression may run in the background to reduce the performance impact. Although post-process compression can reduce the response time for each I/O, it still consumes memory and processor cycles and can affect the overall number of I/Os a storage system can handle. In addition, data initially must be written to disk or flash drives in an uncompressed form, so the physical storage savings are not as great as they are with inline compression.
File system compression
File system compression takes a fairly straightforward approach to reducing the storage footprint of data by transparently compressing each file as it is written.
Many of the popular Linux file systems -- including Reiser4, ZFS and btrfs -- and Microsoft NTFS have a compression option. The server compresses chunks of data in a file and then writes the smaller fragments to storage.
Read-back involves a relatively small latency to expand each fragment, while writing adds substantial load to the server, so compression is usually not recommended for data that is volatile. File system compression can weaken performance, so users should deploy it selectively on files that are not accessed frequently.
Historically, with the expensive hard drives of early computers, data compression software -- such as DiskDoubler and SuperStor Pro -- was popular and helped establish mainstream file system compression.
Storage administrators can also apply the technique of using compression and deduplication for improved data reduction.
Technologies and products that use data compression
Compression is built into a wide range of technologies, including storage systems, databases, OSes and software applications used by businesses and enterprise organizations. Compressing data is also common in consumer devices, such as laptops, PCs and mobile phones.
Many systems and devices perform compression transparently, but some give users the option to turn compression on or off. It can be performed more than once on the same file or piece of data, but subsequent compressions result in little to no additional compression and may even increase the size of the file to a slight degree, depending on the data compression algorithms.
WinZip is a popular Windows program that compresses files when it packages them in an archive. Archive file formats that support compression include ZIP and RAR. The BZIP2 and GZIP formats see widespread use for compressing individual files.
Other vendors that offer compression include Dell with its XtremIO all-flash array and Silk (previously Kaminario) with its K2 all-flash array.
Data differencing
Data differencing is a general term for comparing the contents of two data objects. In the context of compression, it involves repetitively searching through the target file to find similar blocks and replacing them with a reference to a library object. This process repeats until it finds no additional duplicate objects. Data differencing can result in many compressed files with just one element in the library representing each duplicated object.
In virtual desktops, this technique can feature a compression ratio of as much as 100:1. The process is often more closely aligned with deduplication, which looks for identical files or objects, rather than within the content of each object.
Data differencing is sometimes referred to as deduplication.
Editor's note: TechTarget editors revised this article in 2022 to improve the reader experience.







