
Getty Images/iStockphoto
Best practices for a multi-cloud Kubernetes strategy
Multi-cloud has its benefits, but it also creates complexities. Discover best practices and configurations for a multi-cloud strategy using Kubernetes.

It is complicated to create a way to move workloads across one environment and into another -- whether it's cloud based or even on premises. The key to success is to think about implementation details ahead of time. From an architectural perspective, Kubernetes is one way to reduce the complexity in multi-cloud scenarios.
Multi-cloud is a way to scale workloads from one cloud to another. You can connect multiple clouds with proper networking, VPN connectivity and role-based access control (RBAC)/identity and access management authentication and authorization. But when you use multiple environments, they may run on different OSes or have system-specific dependencies. Kubernetes is a popular option for hybrid and multi-cloud because of its portability.
Let's look at multi-cloud and how your organization might benefit from a multi-cloud Kubernetes approach.
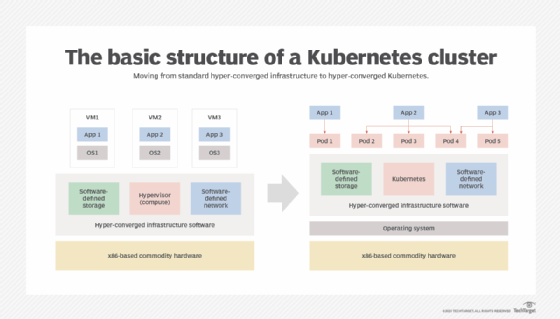
K8s clusters across multiple clouds
Kubernetes is a platform with similar aspects to those in a data center. This includes the following:
- networking
- servers
- storage
- security and policies
- permissions and RBAC
- container images
Workloads within a Kubernetes cluster act as an entire environment inside of one platform. Some engineers call it "the data center of the cloud."
A catastrophic event, such as a flood, can take down the entire environment. With Kubernetes, one catastrophic event in the cluster means hundreds or even thousands of applications would be down. Because of that, disaster recovery is one of the most important aspects of Kubernetes.
Create a multi-cloud Kubernetes strategy
When you design a multi-cloud Kubernetes strategy, you should think about four critical features.
Standardizing cluster policies
Open Policy Agent (OPA) is becoming one of the major standards, in addition to Kyverno, for Kubernetes clusters. Unlike Kyverno, OPA works outside of Kubernetes, so developers can use it across all environments. Also, with OPA, developers can ensure that all Kubernetes Manifests have labels that identify the containerized app and that no container images can use the latest tag. Developers can create anything from overall best practices to specific security best practices.
Track versioning
How you deploy and manage containerized applications is crucial. Taking a Kubernetes Manifest and deploying via localhost by using kubectl apply -f or by running it via a CI/CD pipeline may have been a solid solution in the past. Now, with GitOps, it's no longer necessary. GitOps automatically deploys Kubernetes Manifests. GitOps confirms that the current state of a deployment is the desired state. It does this by using a Git-based repo as the source of truth.
Proper labeling
Tagging resources to fully understand what they are, where they are based out of and how they operate will cause less confusion later. For example, if you have 10 Kubernetes clusters, and they're labeled kubernetes01, kubernetes02, kubernetes03 and so on, you'll never know which cloud they belong to, which region they're in or the type of workloads they're running.
Spread workloads
You want to make sure that you spread workloads -- clusters -- across regions and availability zones. For example, if you use useast-1 in AWS and eastus1 in Azure, they're geographically in similar locations. A natural disaster that affected one, for example, might also affect the other. It would be better to have clusters across regions.
What is multi-cloud?
In the past, organizations relied too heavily on the high scalability of the cloud and thought they could simply turn on a few autoscaling groups and everything would be fine. When that didn't work, organizations had to think about how to scale workloads. Scaling to on premises was an option if the data centers were there -- which is the hybrid cloud model. But what if the data centers didn't exist, or workloads were completely moved out of a data center and the data center was no longer rented to the organization? Thus, multi-cloud was born.
Deploy apps to your clusters using Kubeconfig
This scenario uses the following:
- Azure Kubernetes Service (AKS) and Amazon Elastic Kubernetes Service (EKS) for Kubernetes clusters; and
- Argo CD for GitOps.
If you don't use these platforms, you can still follow along; the principles will be the same.
Step 1. Create and configure clusters
First, you'll need an EKS and AKS cluster. If you prefer to use automation to set up the clusters, check the KubernetesEnvironments GitHub repo.
Step 2. Retrieve contexts
Once you configure the clusters, retrieve both contexts for your Kubeconfig. For example, to pull the contexts from AKS and EKS, use the following commands:
# Azure az aks get-credentials -n name_of_k8s_cluster # AWS aws eks --region region update-kubeconfig --name cluster_name
Step 3. Register the clusters
After you have both contexts in your Kubeconfig, register the AKS and EKS cluster with Argo CD using the following commands:
# Retrieve the context names for AKS and EKS kubectl config get-contexts -o name # Register the contexts argocd cluster add aks_context_name_here argocd cluster add eks_context_name_here
Step 4. Deploy apps
Next, deploy the apps to both clusters:
# AKS argocd app create app_name --repo https://github.com/orgname/reponame.git --path repo_path_where_k8s_manifests_exist --dest-server https:// #EKS argocd app create app_name --repo https://github.com/orgname/reponame.git --path repo_path_where_k8s_manifests_exist --dest-server https://
Turn off the AKS or EKS cluster, creating a hot/cold method. If the EKS or AKS cluster goes down, the other Kubernetes cluster can start, sync to the repo with GitOps and the apps will run again.
This method requires some automation to send an alert for when the EKS cluster goes down. More automation can bring up the AKS cluster and have it sync with GitOps. However, this is a good starting point for a multi-cloud journey.





