
Fotolia
Ask these 5 questions before deploying cloud HA
IT teams can build HA into their organization's cloud apps, but is it worth it? And how much is too much? Ask these and other critical questions before architecting for HA.

When enterprises architect for cloud HA, they need to ask themselves how far they want to take it.
High availability technologies are readily available in the public cloud, and application owners can easily apply additional instances, load balancing, IP addressing schemes, monitoring and other services to build comprehensive cloud HA with almost any level of protection. But every application is different, so you must consider some commonsense self-assessments before layering HA into your organization's cloud infrastructure. You might decide to scale back or even determine that it's best to avoid HA outright.
Editor's note: Click here to read the first part of this tip, which outlines the basics of cloud HA, including the tools that are critical to avoiding downtime and maintaining consistent performance.
Does the workload benefit from HA?
Clearly, critical workloads demand HA, but it's always worth taking a sanity check to ask whether a workload -- and the business -- actually benefits from the complexity and cost. For example, it won't provide any significant benefit for test and development workloads, everyday reporting software or Hadoop clusters that can manage just fine with some minor disruption.
The villains here can often be automation and orchestration. A business establishes provisioning rules and policies for different workload types. Then, a user selects HA workload types simply because the option is available, even though it's not really needed.
Does cloud HA justify the cost?
This is often about applying the appropriate amount of HA. For example, a workload cluster needs at least two redundant nodes, but you can employ many more than that. Each additional node can improve the workload's performance and reliability, but it also adds monthly operating expenses.
Also, consider that a workload with 99.9% availability -- three nines -- can encounter about 43.83 minutes of downtime per month. By comparison, a workload with four nines availability can encounter 4.38 minutes of downtime per month, while a workload with five nines is subject to just 26.3 seconds of downtime per month.
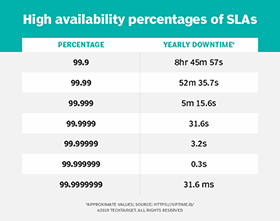
You must determine the maximum allowable downtime for a given workload and then implement just enough HA to ensure those requirements are met. If a workload is alright with 60 minutes of downtime per month, is it really worth trying to achieve more than three nines? Active cloud monitoring and reporting can help to track availability and downtime to verify acceptable availability.
Also, remember that the cloud provider may impose limitations on the availability of its services. Consider that AWS promises a 10% service credit when compute availability falls below 99.99% but remains above 99%. That can result in up to 17 hours and 18 minutes of downtime per month. Some top-tier applications may benefit from being kept on premises where local IT staff can oversee the underlying infrastructure.
Is HA applied to the right assets?
Consider the goal of the cloud HA deployment, and determine precisely what is being protected -- and what actually needs to be protected. For example, more compute nodes are likely appropriate if the goal is to ensure adequate availability and performance. But perhaps it's the workload's data -- not the workload's availability -- that really matters. In such a case, the HA strategy may benefit more from storage replication and other data protection options.
Evaluate what is really valuable about a given workload, and ensure valuable assets are adequately protected with the HA implementation. Otherwise, the deployment may not perform as expected or deliver the required results for the business -- wasting money and effort.
Is HA more complex than necessary?
HA is not a single thing, but rather a wide range of technologies and strategies that can be applied and combined to achieve the desired level of resilience for a workload. What's appropriate for one workload might not work for all workloads. It's important to consider whether the HA technologies applied to each workload are actually right for the intended availability goals. Perhaps there is a simpler, less expensive way to achieve an adequate protection goal.
For example, if the goal is to prevent the loss of vital data, data replication might achieve the required result without the need to implement clusters, load balancing and other technologies. Similarly, if the application can tolerate several minutes of downtime, it could be far less expensive to forego high-end HA in favor of VM snapshot recovery.
Does cloud HA work as intended?
Cloud architects should take the time to evaluate the HA infrastructure and ensure that the deployment works as expected.
On one level, evaluation means reviewing the HA distribution to ensure proper protection against physical events, such as fires or earthquakes, or broader infrastructure events, such as provider or network faults. This should prohibit the placement of multiple compute, storage or other resources within the same cloud region or availability zone.
On another level, evaluation means testing the HA infrastructure on a regular basis to ensure HA meets the established requirements. For example, instances should fail over and fail back within an acceptable time frame without data loss. Also, supporting technologies, such as VM snapshots, should be able to recover and restart a VM within an acceptable time frame. In all cases, it's important to apply monitoring to measure and validate HA behavior. Such validation may be essential to regulatory compliance.
Dig Deeper on Cloud infrastructure design and management
-
![]()
High availability and resiliency are vital to a DR strategy
By: Paul Kirvan
-
![]()
What is high availability (HA)? Definition and guide
By: Robert Sheldon
-
![]()
New SIOS console enables high availability visualization
By: Tim McCarthy
-
![]()
3 best practices to achieve high availability in cloud computing
By: Johanna McDonald


