
Getty Images/iStockphoto
3 best practices to achieve high availability in cloud computing
High availability is the crucial test of whether a business can continue to access data and applications when things go wrong in a cloud-based IT infrastructure.

Availability is an important part of service-level agreements in cloud computing to ensure that infrastructure can continue to function even if a component fails. If there is poor availability, a business is unable to access its data or applications -- and potentially loses revenue.
Availability addresses points of failure within systems, databases and applications. High availability, sometimes referred to as HA, better protects companies from disruptions, and it supports productivity and reliability.
Follow these three best practices to achieve high availability in cloud computing.
1. Determine how much uptime you need
Uptime is a measurement of how long a system properly functions. A service-level agreement (SLA) between a cloud service provider and a customer will state the cloud's expected availability and potential consequences for failing to meet it.
Large providers, such as AWS, Microsoft Azure and Google Cloud, have SLAs of at least 99.9% availability for each paid service. The provider promises its customers that they will experience less than nine hours of downtime over the course of a year. The more nines in the number, the less downtime the customer can expect to experience in a year.
Application complexity can affect uptime. For example, simple websites could see availability of 99.9999% -- approximately 31.6 seconds of downtime each year -- because there are very few points of failure. On the other hand, a more complex monolithic web application that has more components, such as caching servers or object storage, creates more points of failure and may make high availability difficult. Enterprises can employ additional redundancies to ensure uptime, but that increases costs.
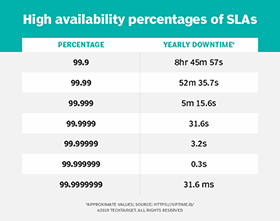
The required amount of uptime an application needs largely depends on how important it is. For example, users visiting a lawn care e-commerce giant's site may be more forgiving if downtime occurs than users of an emergency services provider. When negotiating an SLA with a cloud service provider, a business should weigh the consequences of downtime for its users and what it can afford. Not everything needs 99.999999% availability.
2. Understand core high availability components
High availability may cost a lot of time and money, but it is essential for mission-critical applications. However, the key to high availability is to apply the right amount of resources to a workload. There are many tools to ensure that workloads remain accessible during internal or external disruptions. Organizations should apply the right resources and availability requirements to a given workload to balance reliability and performance with costs.
There are several components to a public cloud platform that organizations should understand to weigh the benefits and costs of high availability:
Physical locations. Organizations achieve high availability through finding and eliminating single points of failure and by distributing redundant instances across availability zones.
Networking. A good network connection is essential when transferring data between the cloud and local storage. Some workloads require dedicated connectivity.
Compute instances. In public clouds, servers take the form of compute instances. A cloud customer can organize those instances into clusters or create backup instances for failover, which can cost more.
Storage instances. Data from applications is kept in storage instances, and cloud storage services are highly available. This removes the need for replication. However, be wary of storage becoming a single point of failure for applications.
Load balancing. Load balancing is how organizations direct traffic to multiple compute instances to accommodate for more load on the instances. Load balancers are often the first component to discover, report and modify an instance failure.
IP cutover. When an instance fails, the IP address of the failed instance must be remapped to the alternate instance to redirect traffic.
Monitoring. In terms of SLAs, monitoring can help to validate uptime availability. It also serves to reveal availability complications as well as track cloud resource usage.
Plan cloud capacity for unexpected spikes
To handle fluctuations in demand for cloud resources, users can scale an application.
Vertical scaling. Also known as scaling up, this method helps avoid failures or slowdowns and processes data at the speed at which it comes in. Cloud admins can handle increased flow by adding more capacity to an instance. While this method is good for a predictable increase, it does not address unexpected spikes beyond the threshold.
Horizontal scaling. Also called scaling out, this process adds instances to a resource pool. It helps solve the problem of increased demand with resources used in larger quantities, rather than increasing the size of individual instances. It should cost less than scaling vertically.
Cloud scaling should be an automated process. In addition to handling spikes, automated scaling should help control costs.
3. Assess application needs before adding HA
It's easy to apply services such as load balancing and IP addressing schemes to the cloud. But every application is different, and cloud users should assess their needs before applying high availability. Before adding high availability to an application, ask these questions:
Does the workload benefit from HA? High availability isn't always the best fit, in terms of cost and complexity. An admin might select a high availability workload type even when it is not necessary.
Does cloud HA justify the cost? Consider the amount of expected downtime and how users will react to this. Then determine the maximum allowable downtime and implement the right high availability strategies to make certain that requirement is met. Monitoring and recording cloud availability and downtime is a way to know the acceptable performance.
Is HA applied to the right assets? Figure out what the organization's goals are, such as optimal performance and workload availability. Evaluate what is the most valuable aspect for the cloud workload and how uptime requirements will benefit these goals.
Is HA more complex than necessary? High availability comes from a wide range of technologies and procedures that can be used or combined. Evaluate whether there is a simpler way to achieve protection from downtime that would cost less money.
Does cloud HA work as intended? Evaluate the high availability setup to make certain the deployment was successful. Review performance against disruption from physical events, such as natural disasters. Audit the infrastructure to ensure the established requirements are being met. If instances fail, they should bounce back within a justifiable time frame and without data loss, as specified in the SLA.






