
Getty Images
Compare Amazon Redshift, Athena and EMR for data analysis
Trying to decide among Amazon EMR, Amazon Redshift and Amazon Athena? Check out this overview of capabilities and use cases to help narrow down your choice.

Organizations often use cloud-based applications to analyze large amounts of data, including system and application logs, business metrics, external data sources, public data sets, input data for machine learning (ML) models and many other scenarios.
AWS, the largest public cloud provider, has a very wide range of services focused on big data and data analytics. These services occasionally have overlapping functionality, which can make it harder to know which one to choose.
Even though these three AWS services are suitable for a wide range of data analysis tasks, before choosing one in particular, it is essential to evaluate the required integrations with relevant systems and data sources. Also, consider the volume of data to be analyzed, perform load tests and evaluate cost according to the specific use case in a particular application.
Let's take a closer look at Amazon Redshift, Amazon Athena and Amazon EMR to help find the right fit for your data analysis needs.
Amazon Redshift
Amazon Redshift is a managed data warehouse that stores and performs data analysis queries in a centralized location. The work is done in a Redshift cluster that consists of one or more compute nodes that also store data. While Redshift supports analyzing data stored in Amazon S3 using Amazon Redshift Spectrum, its main focus is on analyzing data stored in the cluster itself. It also supports a serverless configuration that can access data either stored in Redshift managed storage or externally.
Redshift pulls together data from different sources and stores it in a structured pattern that is defined through databases and tables. It is a highly recommended service for when you need to perform complex queries on massive collections of structured and semistructured data with fast performance. Redshift can automatically ingest data from the following:
- Amazon Relational Database Service (RDS).
- Amazon Aurora MySQL.
- Amazon Kinesis.
- Amazon Managed Streaming for Apache Kafka.
Additionally, other AWS services, such as EMR, Glue and SageMaker, can access the stored data. Redshift can also directly execute ML training and prediction processes on its available data.
Its main model -- provisioned clusters -- makes it difficult to reduce the size of a Redshift cluster based on usage patterns because the data is stored directly in the cluster. This typically results in high cost, given that provisioned Redshift clusters are often always on. IT teams can alleviate this issue with Reserved Instances, which are billed at discounted hourly rates for either a one-year or three-year period. Redshift Serverless is also a money-saving option, which allocates an adjustable compute capacity based on application requirements.
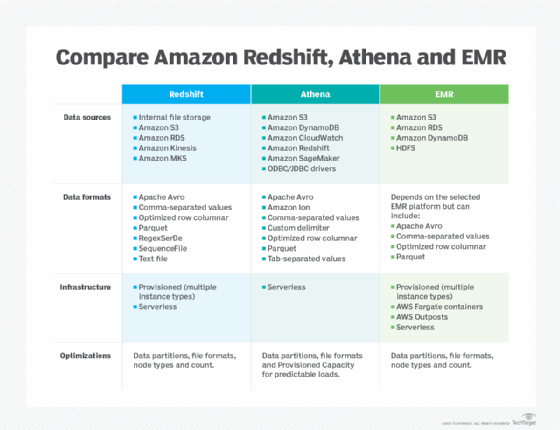
Amazon Athena
Amazon Athena, which is built on open source Trino, Presto and Spark engines, is a serverless service for data analysis on AWS. It is widely used to analyze log data exported to and stored in S3 for services such as the following:
- Application Load Balancer.
- Amazon CloudFront.
- AWS CloudTrail.
- Amazon Data Firehose.
Since it can also access data defined in AWS Glue catalogs, it supports Amazon DynamoDB, CloudWatch, Open Database Connectivity/Java Database Connectivity drivers and Redshift. It also integrates with ML inference endpoints in order to access available ML models through queries defined in Athena.
While this service is the easiest way to get visibility into data stored in S3, services such as EMR or Redshift can potentially bring better performance -- albeit at a potentially higher cost -- since developers can control the underlying infrastructure. It also integrates with Amazon QuickSight for automated data and query result visualizations.
Data analysts use Athena to execute queries using SQL syntax. Users don't have to explicitly configure the underlying compute infrastructure, and in its default configuration, they only pay for data scanned, which makes it a cost-effective tool in most cases. However, for use cases with a constant high volume of transactions, cost might be higher.
Athena is a good fit for infrequent or ad hoc data analysis needs, as users don't have to launch any infrastructure and the service is always ready to query data. Developers can also consider the Athena Provisioned Capacity feature in order to allocate a minimum amount of compute capacity, which is a useful feature for predictable workloads.
Amazon EMR
Amazon EMR, a big data offering, provides managed deployments of popular data analytics platforms, such as Presto, Apache Spark, Apache Hadoop, Apache Hive, Apache Hudi and Apache HBase. EMR automates the launch of compute and storage nodes powered by Amazon EC2 instances, AWS Fargate, on-premises infrastructure managed by AWS Outposts and also serverless.
While data can be stored inside EC2 instances using Hadoop Distributed File System, the service also supports querying data stored in sources outside the cluster, such as S3, DynamoDB or relational databases managed by RDS. EMR managed data can also be accessed by SageMaker for ML training tasks.
EMR makes it possible to adjust the cluster size based on usage requirements and, therefore, optimize cost. It also supports Reserved Instances and Savings Plans for EC2 clusters and Savings Plans for Fargate, which helps with lowering cost.
EMR is a good fit for predictable data analysis tasks, typically on clusters that need to be available for extended periods of time. This includes data loads in which having control over the underlying infrastructure -- i.e., EC2 instances -- optimizes performance and justifies the additional work.
Ernesto Marquez is owner and project director at Concurrency Labs, where he helps startups launch and grow their applications on AWS. He particularly enjoys building serverless architectures, automating everything and helping customers cut their AWS costs.
Dig Deeper on Cloud app development and management
-
![]()
Sample Questions for AWS' Machine Learning Associate Certification
By: Cameron McKenzie
-
![]()
Certified AWS Data Engineer Exam Dumps and Braindumps
By: Cameron McKenzie
-
![]()
Free AWS Data Engineer Associate Practice Exams
By: Cameron McKenzie
-
![]()
Free AWS Certified Data Engineer Sample Questions
By: Cameron McKenzie



