More organizations are embarking on artificial intelligence (AI) and machine learning initiatives to glean better insights from their data, but they likely will face challenges if they lack a structured approach to navigate the entire lifecycle of such projects.
Similar to DevOps practices, a principled approach detailing how data is collected, organized, analyzed, and infused is essential to ensure all information is trusted and adheres to compliance guidelines. This then will drive the accuracy of machine learning models and instill confidence among business users that their AI-powered data insights are impactful.
Often, data needed for building models is spread across multiple data sources and often across multiple clouds. This presents both technical and process-oriented challenges as employees look to access and explore data.
It is technically challenging to pull together data from multiple sources and this is further complicated if the data is stored in different formats. Considerable data engineering time and skill are required to make the data usable.
Organizations also need to adhere to regulations and other restrictions governing user access to data and for what purpose. These are particularly complex in industries such as finance and healthcare.
Furthermore, to facilitate analytics projects, it is common practice to have multiple copies of data stored in different locations and formats. This creates additional problems such as costs, latency, untrustworthy data, and security risks.
Organizations typically also use multiple data science tools, techniques, and frameworks, leading to inconsistent deployment approaches, quality metrics, and poor overall model governance. It also hinders collaboration.
In addition, IT departments often define requirements with regard to training and deploying machine learning models that data science practices must conform to. For example, a training model that uses data stored in a particular cloud must run on the same cloud to minimize data egress charges, or adhere to governance rules.
Not surprisingly, it can be costly and time consuming to deploy data science models into production. For many organizations, the majority of models are never operationalized.
There also are other issues affecting machine learning models, including concerns about AI bias, which can impact user confidence in the predictions generated by these models, as well a lack of governed data lineage for datasets used to train the models.
Organizations that do not resolve these pain points build and operationalize fewer models, resulting in missed opportunities to reduce costs, generate more revenue, mitigate business and financial risks, and improve service delivery.
Enterprises that can overcome these barriers will realize the value data can bring to their decision-making process.
Register to explore the Data Fabric Architecture
Register for this series of workshops today to learn and experience the details of each component of the Data Fabric architecture and how IBM’s data fabric architecture helps your teams intelligently integrate enterprise data for faster innovation and growth.
Download NowEstablish trusted access to realize data value
In fact, by 2022, 90% will have strategies that clearly referenced information as a critical business asset and analytics as an essential competency, Gartner predicts. By then, more than half of major new enterprise systems will be armed with continuous intelligence that taps real-time context data to drive better decision making.
However, the research firm projects that only 5% of data-sharing initiatives in 2022 will correctly identify trusted data and locate trusted data sources. Gartner cautions that businesses that fail to establish access to trusted information will also fail to extract value from their data.
This underscores the importance of standardized practices and processes that define how your data is collected, organized, and analyzed.
With properly governed data, your organization will be better able to comply with complex regulatory and data privacy requirements, and ensure your machine learning models run on only quality data.
Such models also should be continuously monitored and finetuned, so they can generate accurate and meaningful insights as market conditions and consumer demands evolve. Furthermore, AI models must be reasonable and explainable in order for your business decisions to be powered without bias.
Ensuring quality can prove challenging, though, especially as data volume continues to grow exponentially. Companies often struggle to efficiently and securely pull together data from multiple sources, so that all relevant information can be fed into AI models.
Some 28% of AI and machine learning initiatives fail, according to IDC. Its research points to the lack of production-ready data, integrated development environment, and relevant skillsets as primary reasons for failure.
Align DevOps practices with AI model lifecycle
With trustworthy AI a business imperative, organizations must go beyond simply adopting the technology. They need to meld DevOps practices with their machine learning model lifecycle, which then will enable them to fully realize AI at scale.
DevOps practices have accelerated the agility of digitally-savvy businesses, enabling them to quickly gain returns from their application development investments. Based on this success, organizations have started building ModelOps (Model Operations or MLOps) practices that focus on optimizing the delivery of machine learning models.
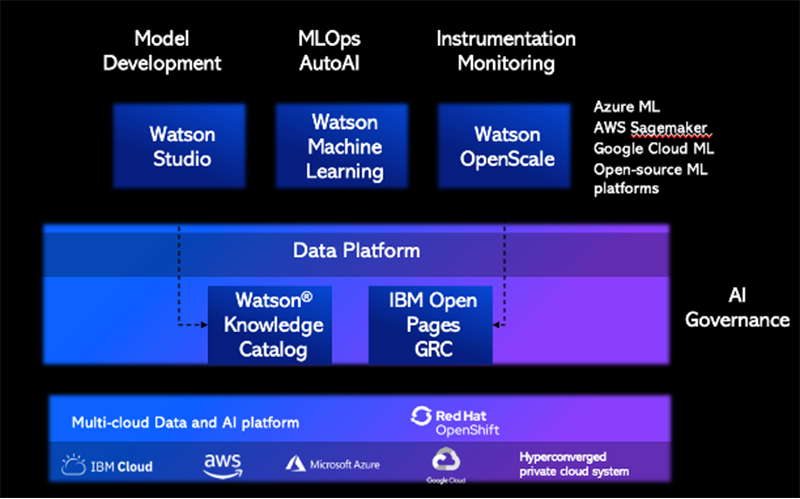
IBM offers range of solutions to help these enterprises establish a robust development and operations infrastructure for their AI and machine learning initiatives. IBM ModelOps, for instance, outlines a principled approach to operationalizing a model in apps, synchronizing cadences between application and model pipelines.
ModelOps tools establish a DevOps infrastructure for machine learning models that span the entire lifecycle, from development to training, deployment, and production.
ModelOps extends your machine learning operations beyond routine deployment of models to further comprise continuous retraining, automated updating, and synchronized development and deployment of more complex models.
Integrated with IBM Watson Studio and Watson Machine Learning, IBM's ModelOps tools also enable organizations to train, deploy, and score machine learning models so these can be assessed for bias.
ModelOps can further accelerate data management, model validation, and AI deployment by synchronizing CICD (continuous integration/continuous development) pipelines across any cloud.
The objective of trusted AI is to deliver data science assets that can be relied upon at scale. Specifically, it focuses on establishing trust in data by ensuring data quality and fairness in the training data, as well as trust in models through explainable model behavior and validation of model performance. Trusted AI also looks to establish trust in the process, which involves the ability to track the model's lifecycle, compliance, and audit preparedness.
IBM Cloud Pak for Data provides the tools and capabilities to ensure enterprises can trust their process, data, and models.
Data integration drives cost, operational efficiencies
Wunderman Thompson understands the need to build a unified data science platform, having faced constraints with siloed databases that were impacting its ability to effectively use predictive modeling.
The New York-based marketing communications agency operates large databases comprising iBehavior Data Cooperative, AmeriLINK Consumer Database, and Zipline Data onboarding and activation platform. These contain billions of data points across demographic, transactional data, health, behavioral, and client domains.
Integrating these properties would provide the foundation the agency needed to build machine learning and AI capabilities and create more accurate models, at scale. It needed to remove the data silos, merge the data in an open data architecture and multicloud environment, and infuse it across the business.
Tapping IBM's Data and AI Expert Labs and Data Science and AI Elite team, Wunderman Thompson built a pipeline that imported data from all its three data sources. Collectively, these databases contain more than 10TB of data gathered from hundreds of primary data sources for over three decades. These include precise data for more than 260 million individuals by age, more than 250 million by ethnicity, language, and religion, as well as more than 120 million mature customers.
Wunderman Thompson subsampled tens of thousands of records for feature engineering, applying decision tree modeling to highlight the most critical data training features. The results showed significant improvements over previous models and an increase in segmentation depth.
With an average change ranging from 0.56% to 1.44%, and a boost of more than 150%, IBM's solutions enabled Wunderman Thompson to discover new personas in its existing databases that it previously was unable to extract.
Using these new insights from data they already had, the agency can better nurture authentic interactions between brands and customers, cultivating deeper and longer engagements.
IBM Cloud Pak for Data offers a wide array of solutions that facilitate multi-cloud data integration, automated data cataloging, and master data management. Built on Red Hat OpenShift, the AI-powered data integration platform better enables businesses to connect data silos and extract actionable insights from their data.
And with ModelOps running on IBM Cloud Pak for Data, enterprises can more easily manage their AI and machine learning initiatives across the entire lifecycle, spanning data organization, building, model development and management, and decision optimization.
Collectively, IBM solutions driver better efficiencies, data quality, data discovery, and governing rules to provide a self-service data pipeline.
As importantly, they increase the success rates of AI and machine learning initiatives, and help deliver clear business value.