
Data may be the new oil, but organizations will need to ensure their data is trusted and authentic so that artificial intelligence (AI) models can generate more accurate, meaningful insights.
It underscores the importance of a robust infrastructure that helps organize all available data and establish the democratization of data. It also ensures governance policies are adhered to and facilitates secured user access to meaningful data, in near-real time.
This is essential especially as data volumes grow and data sources are increasingly varied, residing across different systems and environments, including social media and Internet of Things (IoT) as well as public cloud and on-premises.
If businesses cannot trust the data, they will not be able to trust the decisions the AI models generate. It underscores the need for quality, authentic, and secured data.
Unsurprisingly, data-related issues often are the reasons companies are unable to pull business-ready insights from their AI deployments.
According to IDC, 28% of AI and machine learning projects are estimated to have failed, primarily due to a lack of expertise, production-ready data, and integrated development environment.
The research firm notes that AI deployments continued to be marred by challenges, especially with regards to data. For one, the lack of adequate volumes and quality of training data can proved to be a significant challenge.
IDC further pointed to data quality, quantity, and access as among the top challenges of companies looking to scale and operationalize their AI initiatives.
Left unresolved, such issues can escalate as organizations continue to support remote work, which means employees from different locations will need access to data to make better business decisions.
Orchestrate data for more impactful insights
To establish a robust foundation for AI, enterprises need to be able to quickly access large volumes of data, even if these are spread across different deployments.
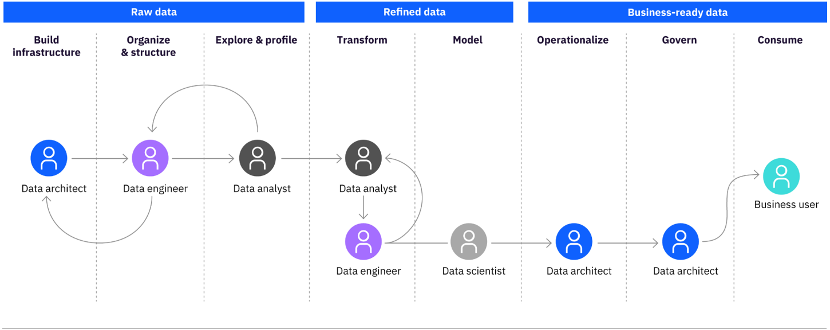
They need a DataOps architecture that helps orchestrate people, processes, and technology to deliver trusted and business-ready data. This data then can better support employees, operations, and applications.
DataOps plugs inefficiencies in discovering, preparing, integrating, and making quality data available to knowledge workers. It facilitates collaboration across the organization, delivering agility, speed, and new data initiatives at scale.
It builds on three key principles around knowing your data, trusting your data, and using your data. It ensures users will be able to find the relevant artifact as well as view all attributes related to the data.
It also establishes quantifiable metrics, such as quality score and social ratings, and enables users to identify critical data elements and automatically assign business terminology to technical artifacts. Knowledge workers then will be able to use the trusted data effectively and build robust data pipelines.
IBM offers a range of solutions designed to drive an organization's DataOps strategy, including IBM Master Data Management, IBM DataStage and Watson Knowledge Catalog. Together, they deliver key capabilities around data governance, data quality, self-service data, data integration, test data management, and reference data management. They create a centralized data catalog and empower users with secured access to data.
With IBM Master Data Management, you will be able to create single, trusted 360-degree view of each customer's interactions with your brand, as well as their preferences and status. Customers can control how much data they want to share and the IBM platform will ensure compliance.
You can then provide personalized communications and options based on this holistic view of your customers, delivering a unique level of customization that goes beyond their expectations.
When data is made business-ready, a modern data catalog system such as IBM Watson Knowledge Catalog will help your organization view, find, and manage large amounts of data. It automatically generates metadata and enables employees to share insights that can improve business operations and service delivery.
Winner of the 2021 iF Design Award for exceptional user experience and innovation, IBM Watson Knowledge Catalog powers intelligent, self-service discovery of data, and data models. It is a cloud-based enterprise metadata repository that drives information for AI, machine learning, and deep learning.
The platform enables businesses to access, curate, categorize, and share data as well as knowledge assets and their relationships, wherever the data resides.
Register to explore the Data Fabric Architecture
Register for this series of workshops today to learn and experience the details of each component of the Data Fabric architecture and how IBM’s data fabric architecture helps your teams intelligently integrate enterprise data for faster innovation and growth.
Download NowEnsure access to trusted, quality data
Apart from establishing a data infrastructure that connects and integrates data across different environments, enterprises also will need to ensure the data itself is of high quality. Only then can the data generate meaningful customer insights and identify opportunities to improve service delivery.
IBM DataStage was built specifically to meet this purpose. It automatically runs validation rules as part of the data ingestion process, reduces silos, and makes data available for use in near-real time.
Coupled with IBM Watson Knowledge Catalog, IBM DataStage helps operationalize data quality by enabling your employees to track data lineage and together score data on quality.
INK Group understands the importance of building a data fabric with such capabilities, especially as increasing manual work, number of subject matter experts, and associated maintenance costs became major obstacles in its ability to extract insights from its centralized data lake.
This was further exacerbated as the Dutch bank moved more data into the cloud and cloud-native applications. It realized it needed to govern data in the cloud the same way as it did on its on-premises environment.
ING tapped IBM Cloud Pak for Data and built an automated abstraction layer that sat between the data and its users, across the bank's hybrid cloud environment. This data fabric adhered to ING's governance policies, including data quality rules, defined business taxonomy, access rights, and data protection across its data sources regardless of the platform on which it resides.
IBM Cloud Pak for Data runs across an open hybrid cloud platform that adapts to ING's multi-platform, heterogeneous landscape, enabling just-in-time access to relevant data across any cloud and on-premises. It does this at the optimum cost and with the appropriate level of governance.
The data fabric solution provides high-quality, governed, business- and regulatory audit-ready data across ING's entire organization, including the different locations in which it operates. The platform automates virtual or physical data integration needs automatically based on data usage patterns.
Like ING, organizations worldwide need to be able to respond quickly as business and market needs change. AI-powered analytics, based on trusted and quality data, can arm them with meaningful business insights they need to deliver better products and services. IBM' Cloud Pak for Data is the AI-based data architecture businesses can depend on to quickly modernize and prepare for deeper digital transformation.
Cloud native by design, Cloud Pak for Data is integrated with automated governance and integration capabilities that span the entire data and analytics lifecycle. It enhances the use of data and AI, and provides the foundation enterprises need to establish a complete view of all data across the organization.
