CrowdStrike disaster exposes a hard truth about IT
Growing third-party dependencies mean more CrowdStrike-like disasters ahead. Preventing these requires a commitment to quality from vendors and robust backup plans from users.
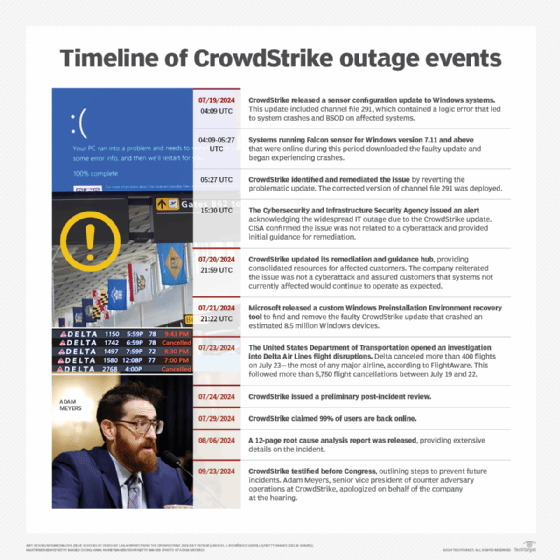
U.S. lawmakers want CrowdStrike CEO George Kurtz to explain how a software update led to thousands of canceled flights, hospital disruptions and emergency call center outages. If Kurtz testifies, he will face hard questions probing CrowdStrike's competency.
Did management issues, inadequate oversight, employee turnover, training, processes, communications, resource allocation and tool investment contribute to this outage? These are critical questions, especially as we adopt AI systems with opaque algorithms that will automate some decision-making and have the potential to do even more damage to our national security and economy.
We are not off to a good start in addressing these issues.
On Wednesday, CrowdStrike released a preliminary post-incident review, which included a list of steps in its rapid response to prevent future occurrences of such global outages. However, it was partly a list of basic software quality practices, such as "local developer testing," where programmers first run tests on their machines.
Local developer testing is merely basic unit testing, which is testing software on a single, isolated machine or environment, said Jim Johnson, who recently retired as the longtime chair of the Standish Group, a research organization that studies software failures.
"I do not see anything in their response that would prevent future issues," Johnson said after looking at CrowdStrike's "software resiliency and testing" prevention plans.
Johnson criticized CrowdStrike for presenting what he sees as standard industry practices as its solution, rather than introducing more rigorous or innovative measures to prevent future outages in its critical security infrastructure.
The businesses disrupted by the CrowdStrike flaw also have a lot of explaining to do.
A failure by CrowdStrike customers
"You can outsource processes, you can outsource jobs, but you can't outsource responsibility," said Daniel Bizo, research director at the Uptime Institute, which advises on critical infrastructure and data center operations.
You can outsource processes, you can outsource jobs, but you can't outsource responsibility.
Daniel BizoResearch director, the Uptime Institute
Some organizations didn't fall to disaster, however, because they had processes to protect themselves.
For instance, although New York City experienced some outages, it didn't affect emergency 911 systems because the city routinely isolates and tests software updates in a sandbox, where an application can't access a system or network. "In this case, there's no luck," said city CTO Matthew Fraser at a briefing shortly after the CrowdStrike outage started. "It's good planning and practice."
The threat of major outages will increase, not just because of the inherent risks in AI systems. Third-party outages are rising as dependencies increase and concentrate among fewer vendors. The Uptime Institute found that third party-related problems resulted in 9% of data center outages in 2023, up from 5% in 2020.
Bizo said the interdependencies of cloud services, networks and service providers are "very difficult to map for even the most resourceful customers."
However, Bizo said organizations must implement contingencies to ensure backup and recovery processes that include third-party systems. Protecting operations includes regular testing, as well as identifying third-party mission-critical dependencies and treating cloud services and security software providers as potential single points of failure, he said.
CrowdStrike's outage cannot be blamed on data and code alone. Companies need to consider testing, backup and recovery strategies even when using third-party providers.
When looking at applications and individual systems, the question is, "What if I lose that? And if I lose that, what's the impact?" Bizo said.
If CrowdStrike executives face Congress, they will deal with lawmakers and staff unlikely to settle for a simple technical explanation. Their capability to take a comprehensive approach was evident in the investigation of Boeing following the crashes of its 737 Max aircraft. The subsequent report detailed as some of the underlying causes technical design flaws, faulty assumptions and management failures at both Boeing and the Federal Aviation Administration.
Herb Krasner, advisory board member and author of the 2022 Consortium for Information and Software Quality's report on "The Cost of Poor Software Quality in the U.S.," said the issue is generally one of "organizational willpower in the C-Suite to do better than they currently are doing." He added, "meaning specifically that quality is not usually an organizational goal -- which is now coming home to roost."
Patrick Thibodeau is an editor at large for TechTarget Editorial who covers HCM and ERP technologies. He's worked for more than two decades as an enterprise IT reporter.