What is the Semantic Web? Definition, history and timeline
The Semantic Web is a vision for linking data across webpages, applications and files. Some people consider it part of the natural evolution of the web, in which Web 1.0 was about linked webpages, Web 2.0 was about linked apps and Web 3.0 is about linked data. The goal of the Semantic Web is to create a machine-readable web of interconnected data that enables better data integration and knowledge sharing.
This vision emphasizes the idea of making data understandable to machines by defining data relationships, meanings and intent. This enables computers to interpret data similarly to how humans process information.
In practice, Semantic Web data is interconnected with metadata that enables machines to define the relationships between different data.
The grand Semantic Web vision is that, eventually, all data will be connected in a single Semantic Web. In practice, today's semantic webs are fractured across specialized uses, including search engine optimization (SEO), business knowledge management and controlled data sharing.
In SEO, all major search engines now support semantic web capabilities for connecting information using specialized schemas about common categories of entities, such as products, books, movies, recipes and businesses, that a person might query. These schemas help generate the summaries that appear in Google search results.
This article is part of
What is Web 3.0 (Web3)? Definition, guide and history
In business knowledge management, companies can use various tools to curate a semantic network -- a graphical representation of entities and their relationships, also known as a knowledge graph -- from information scraped from corporate documents, business services and the public web. This can improve planning, analysis and collaboration in the organization.
Controlled data sharing is more aspirational and experimental. The core idea is that individuals and businesses could create a secure data repository about themselves and their interests and then share links to this data with trusted parties, such as businesses, doctors or government agencies.
The Semantic Web was actually part of computer scientist Tim Berners-Lee's original plan for the World Wide Web, but it was not practical to implement at scale at the time.
Elements of the Semantic Web framework
Berners-Lee proposed an illustration or model called the Semantic Web Stack to help visualize the different kinds of tools and operations that must come together to enable the Semantic Web. The stack can help developers explore ways to go from simply linking to other webpages to linking data and information across webpages, documents, applications and data sources.
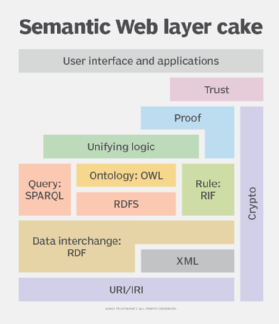
The following is a breakdown:
- At the bottom of the stack, raw data can be expressed using Unicode text characters. Uniform Resource Identifiers can provide links to data within a given page.
- Next up, the Extensible Markup Language is often used to structure information in pages in a machine-readable format.
- Above that, the Resource Description Framework (RDF) provides a standard way for describing entities, properties and the relationships between them for data exchange.
- The Web Ontology Language (OWL) formalizes a way to represent knowledge about and between entities. It works with the World Wide Web Consortium (W3C) Rule Interchange Format to describe things that are harder to formalize.
- The SPARQL query language can search data stored across different sources and work with OWL and RDF to find information.
- Other technologies also need to work with these core semantic processing services to secure data, create an audit trail to enforce trust and provide a user experience.
Semantic Web uses
There are several actual and potential applications of the Semantic Web, including the following:
SEO. This is the most common use of semantic web concepts today. A website owner or content creator adds linked data tags according to standard search engine schemas. This makes it easier for search engines to automatically extract data about, for example, store hours, product types, addresses and third-party reviews. The Rotten Tomatoes website enhanced its click-through rate by 25% when it added structured data.
Automatic summarization. Websites and third-party apps can use tagged data to automatically pull specific types of information from various sites into summary cards. For example, movie theaters can list showtimes, movie reviews, theater locations and discount pricing, which then shows up in searches.
Product detail sharing. Using GS1 Web Vocabulary, manufacturers and wholesalers can automatically transmit information about foods, beverages and other consumer products in a computer-accessible manner across the supply chain. It makes it easier for brands to list information on their websites, such as nutrition labels, product sizes, allergy information, awards, expiration dates and availability dates with grocery stores and online shops that sell their products.
Skill taxonomy standardization. Learning platforms, job websites and human resources teams might all use different terms to describe job skills. Increasingly, enterprises use semantic web technologies to translate different ways of describing skills into a standard taxonomy. This can help teams broaden their applicant search and improve the training programs they develop for employees.
Controlled data access. Consumers often fill out dozens of forms containing the same information -- such as name, address, Social Security number and preferences -- for dozens of different companies. If these organizations are breached, the data is lost to hackers. To address these problems, Berners-Lee's company, Inrupt, is working with various communities, hospitals and governments to roll out data pods built on the Solid open source protocol that let consumers securely share access to their data.
Digital twin data sharing. Several vendors, including Bentley and Siemens, are developing connected semantic webs for industry and infrastructure that they call the industrial metaverse. These next-generation digital twin platforms combine industry-specific ontologies, controlled access and data connectivity to let users view and edit the same data about buildings, roads and factories from various applications and perspectives.
How is the Semantic Web related to Web 3.0? A brief history
The Semantic Web is often called Web 3.0. Berners-Lee started describing something like the Semantic Web in the earliest days of his work on the World Wide Web starting in 1989. At the time, he was developing sophisticated applications for creating, editing and viewing connected data; however, these all required expensive Next workstations, and the software was not ready for mass consumption.
The popularity of the Mosaic browser helped build a critical mass of enthusiasm and support for web formats. The later development of programmable content in JavaScript, which soon became the standard for browser-based programming, opened opportunities for content creation and interactive apps.
Then Tim O'Reilly, founder and CEO of O'Reilly Media, popularized the term Web 2.0 with a conference of the same name. However, Web 2.0 still did not formalize a way to describe the data on a page -- the defining capability of the Semantic Web. Meanwhile, Berners-Lee continued his quest to connect data through his work at the W3C.
The convention of referring to the Semantic Web as Web 3.0 later began to take hold among influential observers. In 2006, journalist John Markoff wrote in The New York Times that a Web 3.0 built on a semantic web represented the future of the internet. In 2007, futurist and inventor Nova Spivak suggested that Web 2.0 was about collective intelligence, while the new Web 3.0 would be about connective intelligence. Spivak predicted that Web 3.0 would start with a data web and evolve into a full-blown Semantic Web over the next decade.
Gavin Wood coined the term Web3 in 2014 to describe a decentralized online ecosystem based on blockchain. Inrupt, which has continued some of Berners-Lee's pioneering work, argues that the Semantic Web is about building Web 3.0, which is distinct from the term Web3. The main point of contention is that Web3's focus on blockchain adds considerable overhead. In contrast, Inrupt's approach focuses on secure, centralized storage controlled by data owners to enforce identity and access control, simplify application interoperability and ensure data governance. Proponents claim that these mechanisms add the missing ingredients required for the Semantic Web to evolve from a platform for better searches to a more connected web of trusted data.

Semantic Web limitations and criticisms
There are a number of challenges involved with creating the Semantic Web.
Combining data
The first generation of semantic web tools required deep expertise in ontologies and knowledge representation. As a result, the primary use has been adding better metadata to websites to describe the things on a page. It requires the extra step of filling in the metadata when adding or changing a page. Content management systems are getting better at it.
However, this only really simplifies the challenges for SEO. Building more sophisticated semantic web applications for combining data from multiple sites is still a difficult problem made more complex by using different schemas to describe data and creative differences in how individuals describe the world.
Vagueness and misunderstandings
Semantic analysis for identifying a sentence's subject, predicate and object is great for learning English, but it is not always consistent when analyzing sentences written by different people, which can vary enormously. Popular buzzwords make things more convoluted, as they can mean different and sometimes contradictory things. For example, while scientists all seem to agree a quantum leap is the smallest change in energy an atom can make, marketers seem to think it is pretty big.
Trust
The other major challenge is building trust in the data represented in a Semantic Web. It is becoming increasingly important to know not only what is written on a page but who said it and what their biases might be. A recommendation from a highly respected source, such as Consumer Reports, will likely have a different weight than one from SpamBot432 on Amazon. Efforts to provide an audit trail for the Semantic Web could help not only connect the data but also help understand data quality and the level of trustworthiness as well.
General feasibility
Full implementation of the Semantic Web relies on widespread adoption of Semantic Web standards and frameworks, but many organizations might lack the technical skills and resources needed. To some, it might not be worth the effort, as traditional web approaches might still be better in scenarios that require unanticipated information resources.
Data privacy
Interlinking data from multiple sources could unintentionally expose sensitive data that bad actors could use to profile other individuals. The Semantic Web would require thorough and extensive privacy protections to avoid any ethical concerns.
Dependency on structured data
The Semantic Web relies on structured and labeled data, which is not always abundant. For example, many websites still rely on unstructured and semistructured data formats that would limit the implementation of a Semantic Web.
Semantic Web vs. semantic search
Search engines, such as Google and Bing, use a search method called semantic search, which is a data searching technique that uses natural language processing (NLP) and machine learning algorithms to improve the accuracy of search results. This search method aims to identify the searcher's underlying objective and to find contextually relevant results, even if they don't contain the exact words used in the original query. By comparison, traditional lexical searches can only find direct keywords used in the search query.
Semantic search is a practical application of the broader concept of the Semantic Web. The Semantic Web and semantic search share a number of the same underlying technologies, such as RDF, OWL, SPARQL and knowledge graphs. Semantic search, however, also uses technologies such as NLP and machine learning on top of this.
While a Semantic Web focuses on creating a machine-readable data-based web, semantic search focuses on a user-centric use case.
The future of the Semantic Web
While web search engines, including Google and Bing, use semantic search, it is just the start of implementing a Semantic Web. Although a future with a functioning Web 3.0 with a Semantic Web behind it is possible, this vision and its potential impact is still a ways away.
An increasing number of websites automatically add semantic data to their pages to boost search engine results. But there is still a long way to go before this data is fully interconnected across webpages. Translating the meaning of data across different applications is a complex problem to solve.
Innovations in AI and NLP are helping to bridge some of these gaps, particularly in specific domains such as skill taxonomies, contract intelligence and digital twins. The future might involve a hybrid approach combining better governance of the schemas an organization or industry uses to describe data and AI and statistical techniques to fill in the gaps. Getting closer to the original vision of a web of connected data will require a combination of better structure, better tools and a chain of trust.
Internet of things (IoT) devices might also benefit from the Semantic Web, as it can provide the interoperability needed to manage the large amounts of data generated by IoT devices.
The Semantic Web is a big part of what makes up Web 3.0. Learn more about some of the potential advantages and disadvantages of Web 3.0.







