Databricks adds new ML modeling tool to lakehouse platform
The machine learning modeling tool eliminates the need for users to manage complex serving infrastructures by enabling them to launch machine learning models as REST APIs.
Databricks on Tuesday launched Model Serving, a tool that enables users to deploy machine learning models as REST APIs on the vendor's lakehouse platform and eliminates the need to manage a serving infrastructure.
Founded in 2013 and based in San Francisco, Databricks is data lakehouse vendor whose platform offers a combination of the structured data storage capabilities of a data warehouse with the unstructured data storage capabilities of a data lake.
The lakehouse structure is designed to enable data teams to quickly and easily access data and provide users with the most current data for use in data science, machine learning (ML) and analytics projects.
Most recently, Databricks unveiled Visual Code Extension. The feature lets developers build analytics, augmented intelligence and ML models with Microsoft's Visual Studio Code -- an integrated development environment -- before moving it into Databricks' lakehouse architecture.
New capabilities
Before the launch of Model Serving, users often had rely on batch files to move data into a cache within a data warehouse where they could build and train a model before moving the model back into an application where it could be used for analysis.
Now, using the new capability -- generally available now -- Databricks customers can build and deploy real-time ML applications, such as customer service chatbots and personalized recommendation systems, more simply.
By enabling users to deploy the models to the Databricks lakehouse as REST APIs, the vendor said it is eliminating the need for customers to build and manage complex machine learning infrastructures made up of a slew of tools from various vendors.
In addition, Model Serving comes with prepackaged integrations with other Databricks tools, including MLflow Model Registry for deployment and Unity Catalog for governance. Those integrations enable users to natively manage the entire ML process -- including automating aspects of it -- and removes the need to batch and cache models before moving them to the Databricks lakehouse.
Ultimately, simplification of the ML modeling and deployment process is the key benefit of Model Serving, according to Matt Aslett, an analyst at Ventana Research.
"Model Serving … expands Databricks' capabilities beyond batch serving and complements the company's existing functionality by providing integration with its feature store, MLOps and governance capabilities," he said. "The combination of this functionality should enable customers to simplify model development and deployment."
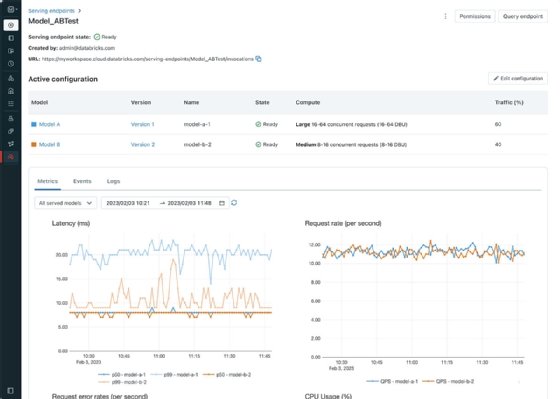
A sample Databricks screenshot displays test results for a machine learning model.
In particular, a simplified ML modeling and deployment process will help with applications such as chatbots and recommendation engines that need to act and react in real time and are becoming more ubiquitous at many organizations, Aslett continued.
"We are seeing a shift toward real-time inference," he said. "Organizations see the need to reduce the cost, complexity and time taken to deliver analytic insights to data-intensive operational applications … such as personalization and artificial intelligence-driven recommendations."
Like Aslett, Craig Wiley, senior director of product development for Databricks, said that simplification is the key benefit of the system.
He noted that thanks to low-code modeling tools, developing augmented intelligence and ML models has become easier in recent years. However, more than half of all models still fail to ever make it into production. This is often the result of the complexity of deploying, updating and re-training models to make and keep them useful.
Model Serving attempts to remove much of that complexity and make ML model deployment more successful.
"We want to simplify the customer's process of finding value from their data," Wiley said. "And in doing that, we want to make it easier for them to build and deploy ML. Companies are investing tremendous amounts of resources in advanced analytics, machine learning and AI. And we want to make sure they can achieve a strong return on those investments."
Model Serving fills in what was a missing piece in the Databricks lakehouse platform, he added.
The vendor already provided automated machine learning capabilities, a feature store for ML and environments for model training. But deployment remained difficult.
Customers could build the models, but then they needed help moving them into Kubernetes clusters or other ML serving tools, according to Wiley.
"That always came with the tax of technical complexity," he said. "So our goal with this was to simplify that process and help customers achieve a higher ROI on their ML investments."
While Model Serving simplifies the development and deployment of ML models to the Databricks lakehouse, Aslett noted that other vendors offer similar capabilities.
"Databricks is not alone in bringing these capabilities together, although it does offer a breadth and depth of functionality that not all other providers can match," Aslett said.
Product plans
Model Serving went through a lengthy evolution while in beta testing, according to Wiley.
Serverless Real-Time Inference … expands Databricks' capabilities beyond batch serving and complements the company's existing functionality by providing integration with its feature store, MLOps and governance capabilities.
Matt AslettAnalyst, Ventana Research
Initially, Databricks made the model the focus of the tool. But as feedback from customers came in, the vendor pivoted to make the API the focal point to make it easier to update and remain actionable.
Moving forward, Wiley said Databricks plans to improve the model monitoring capabilities of Model Serving and add support for graphics processing units so users can build larger deep learning models.
"We're excited to expand the number and size and scale of models that can be used," he said.
Beyond Model Serving, the roadmap for the Databricks lakehouse platform includes deeper integration between the vendor's ML stack and its data stack, Wiley continued. He noted that ML and data stacks are often isolated from each other, and Databricks is attempting to bring the two together.
"We're trying to build an integrated ML stack that's deeply connected to the data stack," Wiley said.
Eric Avidon is a senior news writer for TechTarget Editorial and is a journalist with more than 25 years of experience. He covers analytics and data management.