TigerGraph 3.2 targets platform's performance, ease of use
Enterprise-grade performance and ease of use are the key areas of the latest platform update from the startup graph database vendor as it looks to attract more enterprise customers.
Designed with ease of use and performance at scale as central principles, TigerGraph on Tuesday released the latest version of its platform.
TigerGraph, founded in 2012 and based in Redwood City, Calif., is a graph database vendor.
The vendor's platform, based on graph technology that that enables data points to simultaneously connect to multiple other data points, aims to drive faster and more accurate data exploration than traditional relational databases in which data points are only able to connect to one other data point at a time.
The vendor unveiled TigerGraph 3.2, which includes more than 40 new and upgraded capabilities, during Graph + AI Summit Fall 2021, the autumn edition of its hybrid conference running virtually and in person in San Francisco on Oct. 5 and virtually and in person in New York on Oct. 19.
Platform update
New and upgraded tools included in TigerGraph 3.2 and now generally available include enterprise-grade capabilities aimed at large organizations that manage and produce copious amounts of data, features designed to simplify content development and tools intended to enable data scientists to more easily build machine learning models.
"The first theme of the release is enterprise manageability and supportability, which is tied to performance," said Jay Yu, TigerGraph's vice president of product innovation. "It's really about usability, saving the time that leads to productivity. That's the key -- productivity and ease of use."
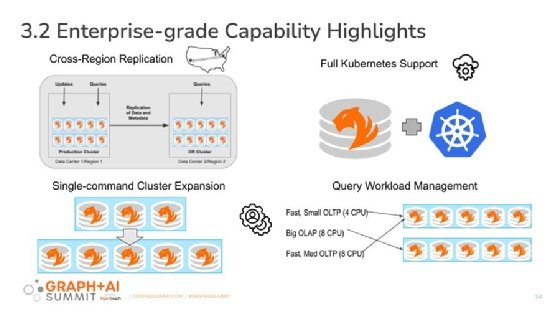
Among the new enterprise-grade capabilities are cross-region replication, providing customers that deploy in one region with active, replicated versions of those queries in real time in other regions where they deploy. Previously, customers had to build their own replications. Cloud data warehouses such as Amazon RedShift and public clouds such as Microsoft Azure are broken into regions.
The latest version of TigerGraph's platform, unveiled Oct. 5, includes cross-region replication and full support for Kubernetes.
In addition, TigerGraph has built-in full Kubernetes support, enabling customers to use Kubernetes to manage their deployment in the cloud. Before TigerGraph 3.2, the vendor offered only partial support for Kubernetes.
Cluster resizing is a third new enterprise-grade feature, enabling customers to expand the size of clusters so they can quickly and easily run queries on larger amounts of data.
New tools designed for developers, meanwhile, include about 30 prebuilt functions that enable complex queries without having to write code; the modernization of TigerGraph's query language to make writing queries more closely resemble writing queries with SQL; and enhancements to GraphStudio that make it compliant with Web Content Accessibility Guidelines designed to make web content more accessible to people with disabilities.
It's really about usability, saving the time that leads to productivity. That's the key -- productivity and ease of use.
Jay YuVice president of product innovation, TigerGraph
Finally, capabilities aimed at enabling data scientists include the ability to run algorithms directly in the database, the addition of a library for algorithms, and increased database scalability so TigerGraph can run dozens of terabytes at once.
Both cross-region replication and full support for Kubernetes are key new capabilities as TigerGraph aims to improve performance for enterprise customers, according to Doug Henschen, analyst at Constellation Research.
"From a scale perspective, TigerGraph was differentiated from its beginnings in being a massively parallel processing database," he said. "The latest release builds on that scalability advantage with features including support for cross-region replication in cloud deployments and Kubernetes-based cloud management."
Meanwhile, in terms of addressing ease of use, Henschen added that simplified cluster resizing, faster backup and restore, and direct control over resource allocation for big queries are all significant.
"I'd also point to all the work they've done to expose graph capabilities to SQL-savvy developers through their GSQL language," he said.
According to Yu, most of the capabilities included in TigerGraph 3.2 were on the vendor's roadmap, but their inclusion in this particular platform update was spurred by customer input.
"Development is a combination," he said. "The more we grow our customer base, the more mission-critical it is to support enterprise scale. These features were on the roadmap, but we accelerated the development of some based on customer requirements. We know we want to build them all, but as a startup we have limited resources and we don't know when we can work on them."
TigerGraph's attempt to meet the requirements of customers is particularly evident in the new capabilities aimed at data scientists, according to Henschen.
He noted that that relational database vendors have added in-database data science capabilities, but TigerGraph has been at the forefront of adding such capabilities to graph databases.
"Rather than just adding generic, general-purpose data science capabilities, TigerGraph has gauged the needs of its customers and gone after specific use cases, including fraud detection, anti-money laundering, identity resolution and recommendation engines," Henschen said. "That simplifies the development of high-scale graph use cases in specific industries."
According to Yu, TigerGraph 3.2 is a bigger update than most the vendor has released in the past, and as a result it took six months to put together rather than the three it normally takes.
In addition, he said the features included in the update are being made available in the on-premises version of TigerGraph's platform first. The vendor needs to do more work before cloud-based versions of the new capabilities are ready, but Yu said he expects them to be generally available by the end of October.
What's next
Looking ahead, Yu said TigerGraph will look to add more scalability to its platform.
TigerGraph currently can quickly handle queries on up to 36 terabytes of data -- the Linked Data Benchmark Council industry standard benchmark is one terabyte, according to Yu -- and aims to increase that to 100 terabytes.
In addition, TigerGraph's roadmap includes support for GraphQL, the standard query language for developers, and the addition of Visual Query Builder to enable no-code querying and prebuilt industry-specific vertical features to simplify adoption.