What is a data rollup?
Learn what a data rollup is and read about data rollup macro examples and case studies in this data mining tutorial from the book Data Mining: Know it All.
 Data Mining: Know it All
Data Mining: Know it All
In this excerpt from Data Mining: Know it All, learn what data rollup is, discover how it relates to data mining projects and read examples of how to complete the data rollup process.
2.4 Data Rollup
The simplest definition of data rollup is that we convert categories to variables. Let us consider an illustrative example.
Table of contents:
An introduction to data mining
Simple data mining examples and datasets
Fielded applications of data mining and machine learning
The difference between machine learning and statistics in data mining
Information and examples on data mining and ethics
Data acquisition and integration techniques
What is a data rollup?
Calculating mode in data mining projects
Using data merging and concatenation techniques to integrate data
Table 2.1 shows some records from the transaction table of a bank where deposits are denoted by positive amounts and withdrawals are shown as negative amounts. We further assume that we are building the mining view as a customer view. Because the first requirement is to have one, and only one, row per customer, we create a new view such that each unique customer ID appears in one and only one row. To roll up the multiple records on the customer level, we create a set of new variables to represent the combination of the account type and the month of the transaction. This is illustrated in Figure 2.1. The result of the rollup is shown in Table 2.2.
Table 2.1 A Sample of Banking Transactions
| Customer ID | Date | Amount | Account type |
| 1100-55555 | 11Jun2003 | 114.56 | Savings |
| 1100-55555 | 21Jun2003 | − 56.78 | Checking |
| 1100-55555 | 07Jul2003 | 359.31 | Savings |
| 1100-55555 | 19Jul2003 | 89.56 | Checking |
| 1100-55555 | 03Aug2003 | 1000.00 | Savings |
| 1100-55555 | 17Aug2003 | − 1200.00 | Checking |
| 1100-88888 | 14June2003 | 122.51 | Savings |
| 1100-88888 | 27June2003 | 42.07 | Checking |
| 1100-88888 | 09July2003 | − 146.30 | Savings |
| 1100-88888 | 09July2003 | − 1254.48 | Checking |
| 1100-88888 | 10Aug2003 | 400.00 | Savings |
| 1100-88888 | 11Aug2003 | 500.00 | Checking |
Table 2.1 shows that we managed to aggregate the values of the transactions in the different accounts and months into new variables. The only issue is what to do when we have more than one transaction per account per month. In this case, which is the more realistic one, we have to summarize the data in some form. For example, we can calculate the sum of the transactions values, or their average, or even create a new set of variables giving the count of such transactions for each month – account type combination.
It is obvious that this process will lead to the generation of possibly hundreds, if not thousands, of variables in any data-rich business applications. Dealing with such a large number of fields could present a challenge for the data preparation and data mining software tools. It is therefore required that we keep the number of these new fields to a minimum while keeping as much information about the nature of the data as possible. Unfortunately, there is no magic recipe to achieve this balance. However, a closer look at the preceding data reveals that the key to controlling the number of new variables is to decide on the level of granularity required to perform the rollup. For example, is it necessary to roll up the transactions of each month, or is it enough to roll up the data per quarter? Similarly, in our simplified case, we had only two categories for the account type, but typically, there would be many more categories. Then comes the question of which categories we can group together, or even ignore, to reduce the number of new variables.
Figure 2.1 Data rollup
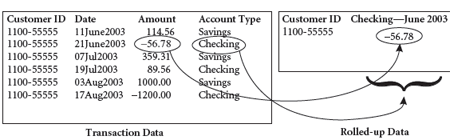
Table 2.2 Result of Rolling up the Data of Table 2.1
| Cust. ID | C-6 | C-7 | C-8 | S-6 | S-7 | S-8 |
| 1100-55555 | − 56.78 | 89.56 | − 1200.00 | 114.56 | 359.30 | 1000.00 |
| 1100-88888 | 42.07 | − 1254.00 | 500.00 | 122.51 | − 146.30 | 400.00 |
In the end, even with careful selection of the categories and resolution of combining the different categories to form new variables, we usually end up with a relatively large number of variables, which most implementations of data mining algorithms cannot handle adequately. However, we should not worry too much about this problem for the moment because data reduction is a basic step in our planned approach. In later chapters, we will investigate techniques to reduce the number of variables.
Copyright info
Printed with permission from Morgan Kaufmann, a division of Elsevier. Copyright 2009. Data Mining: Know It All by Chakrabarti et all. For more information about this title and other similar books, please visit www.elsevierdirect.com.
In the last example demonstrating the rollup process, we performed the rollup on the level of two variables: the account type and the transaction month. This is usually called multilevel rollup. On the other hand, if we had had only one type of account, say only savings, then we could have performed a simpler rollup using only the transaction month as the summation variable. This type of rollup is called simple rollup. In fact, multilevel rollup is only an aggregation of several simple rollups on the row level, which is the customer ID in our example. Therefore, data preparation procedures, in either SAS or SQL, can use this property to simplify the implementation by performing several simple rollups for each combination of the summarization variables and combining them. This is the approach we will adopt in developing our macro to demonstrate the rollup of our sample dataset.
More on data mining:
- Download a PDF of this chapter for free: "Data Acquisition and Integration"
- Read other excerpts from data management books in the Chapter Download Library.
Now let us describe how to perform the rollup operation using SAS. We will do this using our simple example first and then generalize the code using macros to facilitate its use with other datasets. We stress again that in writing the code we preferred to keep the code simple and readable at the occasional price of efficiency of execution, and the use of memory resources. You are welcome to modify the code to make it more efficient or general as required.
We use Table 2.1 to create the dataset as follows:
Data Transaction;
Informat CustID $10.;
Informat TransDate date9.;
format TransDate Date9.;
| input CustID $ | TransDate | Amount | AccountType$; Cards; |
| 55555 | 11Jun2003 | 114.56 | Savings |
| 55555 | 12Jun2003 | 119.56 | Savings |
| 55555 | 21Jun2003 | − 56.78 | Checking |
| 55555 | 07Jul2003 | 359.31 | Savings |
| 55555 | 19Jul2003 | 89.56 | Checking |
| 55555 | 03Aug2003 | 1000.00 | Savings |
| 66666 | 22Feb2003 | 549.56 | Checking |
| 77777 | 03Dec2003 | 645.21 | Savings |
| 55555 | 17Aug2003 | − 1200.00 | Checking |
| 88888 | 14Jun2003 | 122.51 | Savings |
| 88888 | 27Jun2003 | 2.07 | Checking |
| 88888 | 09Jul2003 | − 146.30 | Savings |
| 88888 | 09Jul2003 | − 1254.48 | Checking |
| 88888 | 10Aug2003 | 400.00 | Savings |
| 88888 | 11Aug2003 | 500.00 | Checking |
; run;
The next step is to create the month field using the SAS Month function:
data Trans;
set Transaction;
Month = month(TransDate);
run;
Then we accumulate the transactions into a new field to represent the balance in each account:
proc sort data = Trans;
by CustID month AccountType;
run;
* Create cumulative balances for each of the accounts * /
data Trans2;
retain Balance 0;
set Trans;
by CustID month AccountType;
if first.AccountType then Balance = 0;
Balance = Balance + Amount;
if last.AccountType then output;
drop amount;
run;
Finally, we use PROC TRANSPOSE to roll up the data in each account type and merge the two resulting datasets into the final file:
/ * Prepare for the transpose * /
proc sort data = trans2;
by CustID accounttype;
run;
proc transpose data = Trans2 out = rolled C prefi x = C ;
by CustID accounttype;
ID month ;
var balance ;
where AccountType = ' Checking ' ;
run;
proc transpose data = Trans2 out = rolled S prefi x = S ;
by CustID accounttype;
ID month ;
var balance ;
where AccountType = ' Savings ' ;
run;
data Rollup;
merge Rolled S Rolled C;
by CustID;
drop AccountType Name ;
run;
To pack this procedure in a general macro using the combination of two variables, one for transaction categories and one for time, we simply replace the Month variable with a TimeVar, the customer ID with IDVar, and the AccountType with TypeVar. We also specify the number of characters to be used from the category variable to prefix the time values. Finally, we replace the two repeated TRANSPOSE code segments with a %do loop that iterates over the categories of the TypeVar (which requires extracting these categories and counting them). The following steps detail the resulting macro.
Figure 2.3 Parameters of TBRollup() Macro
| Header Parameter | TBRollup (TDS, IDVar, TimeVar, TypeVar, Nchars, Value, RDS) Header Parameter Description |
| TDS | Input transaction dataset |
| IDVar | ID variable |
| TimeVar | Time variable |
| TypeVar | Quantity being rolled up |
| Nchars | Number of characters to be used in rollup |
| Value | Values to be accumulated |
| RDS | The output rolled up dataset |
Step 1
Sort the transaction file using the ID, Time, and Type variables:
proc sort data = & TDS; by & IDVar & TimeVar & TypeVar; run;
Step 2
Accumulate the values over time to a temporary _Tot variable in the temporary table Temp1 (see Table 2.3 ). Then sort Temp1 using the ID and the Type variables: data Temp1;
retain _TOT 0;
set & TDS;
by & IDVar & TimeVar & TypeVar;
if fi rst. & TypeVar then _TOT_ = 0;
_TOT = _TOT & Value;
if last. & TypeVar then output;
drop & Value;
run;
proc sort data= Temp1;
by & IDVar & TypeVar;
run;
Step 3
proc freq data = Temp1 noprint;
tables & TypeVar /out = Types ;
run;
data null ;
set Types nobs = Ncount;
if & typeVar ne " then
call symput( ' Cat ' | | left( n ), & TypeVar);
if N = Ncount then call symput( ' N ' , Ncount);
run;
Step 4
Loop over these N categories and generate their rollup part: %do i = 1 %to & N;
proc transpose
data = Temp1
out = R & i
prefi x = %substr( & & Cat & i, 1, & Nchars) ;
by & IDVar & TypeVar;
ID & TimeVar ;
var TOT ;
where & TypeVar = " & & Cat & i " ;
run;
%end;
Step 5
Finally, assemble the parts using the ID variable:
data & RDS;
merge %do i = 1 %to & N; R & i %end ; ;
by & IDVar;
drop & TypeVar Name ;
run;
Step 6
Clean the workspace and finish the macro:
proc datasets library = work nodetails;
delete Temp1 Types %do i=1 %to & N; R & I %end; ;
run;
quit;
%mend;
We can now call this macro to roll up the previous example Transaction dataset using the following code:
data Trans;
set Transaction;
Month = month(TransDate);
drop transdate;
run;
| %let IDVar | = CustID; | / * The row ID variable * / |
| %let TimeVar | = Month; | / * The time variable * / |
| %let TypeVar | = AccountType; | / * The Type variable * / |
| %let Value | = Amount; | / * The time measurement variable * / |
| %let Nchars | = 1; | / * Number of letters in Prefix * / |
| %let TDS | = Trans; | / * The value variable * / |
| %let RDS | = Rollup; | / * the rollup file * / |
| = colspan="3"> %TBRollup( & TDS, & IDVar, & TimeVar, & TypeVar, & Nchars, & Value, & RDS); |
The result of this call is shown in Table 2.4.
Table 2.4 Result of Rollup Macro
| CustID | C6 | C7 | C8 | C12 | S6 | S7 | S8 | S12 |
| 5555 | − 56.78 | 89.56 | − 1200 | -- | 234.12 | 359.31 | 1000 | --- |
| 6666 | -- | -- | -- | 549.56 | -- | -- | -- | -- |
| 7777 | -- | -- | -- | -- | -- | -- | -- | 645.21 |
| 8888 | 42.07 | − 1254.48 | 500 | -- | 122.51 | − 146.3 | 400 | -- |







