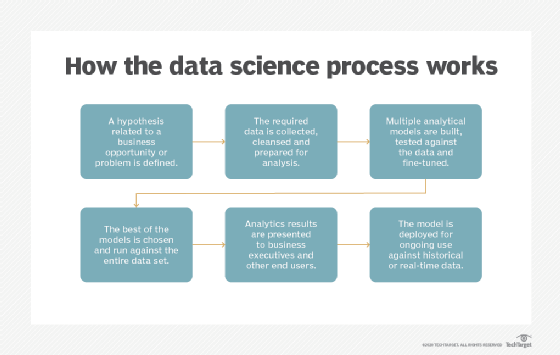
The data science process: 6 key steps on analytics applications
The data science process includes a set of steps that data scientists take to gather, prepare and analyze data and present the analytics results to business users.
Data is the lifeblood of modern businesses. Increasingly, getting the most out of our organization's data with accurate insight and understanding makes a real difference to business success. As a result, the data scientist has become a critical hire for companies of all sizes, whether the job is a specialized position in IT or embedded in a business unit.
Nevertheless, it isn't always clear what we mean by the term data scientist. A highly qualified data analyst? Someone with a scientific background who happens to work with data?
Certainly, data scientists typically are experienced in statistics and scripting, and they often have a technical background, rather than a scientific, liberal arts or business one. But the critical element of data science -- which does make it a science rather than just a business practice -- is the importance of process and experiments.
You likely remember learning about the scientific method in high school. Scientists come up with theories and hypotheses. They design experiments to test those hypotheses and then either confirm, reject or, more often, refine the theory.
Basic business intelligence and reporting typically doesn't follow this process. Instead, BI and business analysts sift, sort, tabulate and visualize data in order to support a business case. For example, they may show graphically that sales of our company's products in the western region are falling and also that this region includes more younger customers compared to other areas. From there, they could make the case that we need to change our product, marketing or sales strategy for that region. In BI, the most persuasive data visualization often carries the argument.
The data scientist takes a different approach. Let's continue to use this sales example to show how the data science process works, in the following six steps.
The data science process includes these six steps.
1. Identify a hypothesis of value to the business
In our case, the data scientist can formulate a simple hypothesis based on questions raised by the sales, marketing and product teams: We think younger people are less likely to buy our products, so that's driving down sales in the relatively youthful western region.
In addition, we could come up with a few related hypotheses, such as: It's not simply that customers in the western region are younger, but also that younger people typically earn less money and average income is lower there than it is in other regions.
You can see already that the data scientist must be able to think through different implications of related hypotheses in order to design the right data science experiments. Just asking one direct question when analyzing data generally proves less helpful than asking several. And to get the best results, data scientists should work with business experts to tease out edge cases and counterexamples that can help refine their hypotheses.
2. Gather and prepare the required data
With a hypothesis or a set of them in hand, it's time for the data scientist to get the right data and prepare it for analysis.
The BI team commonly works with data from a data warehouse that has been cleaned up, transformed and modeled to reflect business rules and how analysts have looked at the data in the past. The data scientist, on the other hand, generally wants to look at data in its raw state, before any rules are applied to it. Also, data science applications often require more data than what is stored in a warehouse.
In our example, the company's data warehouse likely includes various details about customers but perhaps not how they paid for products: by credit card, cash, online payment, etc. Or we may find that, because data warehouse models can be cumbersome to modify, the putative system of record is a little out of date and doesn't yet include newer forms of payment -- exactly the kinds that are attractive to younger people.
So, the data scientist needs to work with the IT team to get access to the most detailed data sources that are available and pull together the required data. This may be business data sourced from ERP, CRM or other operational systems, but it increasingly also includes web logs, streaming data from IoT devices and many other types of data. The raw data usually will be extracted and loaded -- or ingested, as the jargon has it -- into a data lake. For simplicity and convenience, though, the data scientist most often only works against a sample data set at this early stage.
And this isn't to say that data scientists do no data preparation work at all. For sure, they typically don't apply business models or predefined business rules to the raw data in the manner of a data warehouse developer. But they do spend a lot of time profiling and cleansing data -- for example, deciding how to handle missing or outlier values -- and transforming it into structures that are appropriate for specific machine learning algorithms and statistical models.
3. Experiment with and tune analytical models
Designing the experiment is a critical step in the data science process. Indeed, some would say it's more of an art than a science. Certainly, it helps if the data scientist has a good understanding of the business and some insight into what constitutes interesting variables to consider, in addition to a sense of which algorithms are likely to give more useful results.
Today, there are numerous data science and machine learning tools that can try different algorithms and approaches and select the best ones for analytics applications, without much human intervention. You more or less point the tool at the data, specify the variables you're interested in and leave it to run. Often described as automated machine learning platforms, these systems are largely marketed to business users who function as citizen data scientists, but they're just as popular with skilled data scientists, who use them to investigate more models than they could do manually.
Even the best model can be improved with some tuning and tweaking of variables. Sometimes, the data scientist may even want to go back and shape the data a little differently -- perhaps removing outliers that were left during the initial data preparation stage. For example, I've seen many cases where the original data was collected with default values that were convenient but wrong and potentially misleading.
4. Select a model and run the data analysis
Once the data scientist has found the best algorithm running against the test data set, it's time to run the analytics experiment against all of the data.
With an interesting hypothesis, good data and a carefully built model, a data scientist should be able to find something useful to the business.
The results? Well, I can't tell you what they'll be. But, with an interesting hypothesis, good data and a carefully built model, a data scientist should be able to find something useful to the business. You may surprise yourself, even at this stage, with an unexpected discovery. Most often, you'll either confirm or reject your original hypothesis -- which, of course, is what you set out to do in the first place.
Going back to our sales example, let's assume the model we decide to run proves that, yes, younger people are less likely to buy our products -- but with some important twists, which leads us to the next step.
5. Present and explain the results to business stakeholders
Remember that the whole point of our experiment was to test some ideas that we can then take to marketing, sales and product design to give them new insights into our customers.
What we have, however, is a mass of statistics from our model that the business users may not understand. Perhaps in general, younger people are indeed less likely to buy our product -- also, their average purchase is lower than those of older customers. But some young people buy a lot, resulting in a high median sale level.
To help business stakeholders understand such complications, data scientists need another skill -- not an additional technical ability, but one of a set of soft skills they should have. They must be able to explain the analytics work and tell the story of the data science experiment and its results. Some businesses even have data interpreters or analytics translators who specialize in this important task, describing the implications of analytical models and their findings in business terms. They and data scientists alike often use data storytelling techniques to clarify the analytics results and proposed actions.
6. Prepare and deploy the model for production use
We now have our data in place, our model working and a good business understanding of what we have discovered. In fact, the business teams have even thought about how to make some offers on our website to appeal to those elusive younger customers in the west. Now we need to take the data science work from the lab and put it into production on operational data as the business is running.
This final step isn't always straightforward. First, updating the analytical model with fresh data on an ongoing basis may require a different approach to data loading. What we did manually as an experiment may not be efficient in practice. Partly for this reason, another role has emerged in many businesses: the data engineer, whose responsibilities include working closely with data scientists to make models production-ready.
We should also recognize that, in our example, buying habits change over time, perhaps with the economy or changes in taste. So, we have to keep the model up to date and perhaps tune it again in the future. That may also be one of a data engineer's tasks, although the data scientist must rework a model if it drifts too much from its original accuracy.
Finally, the model that works best as an experiment may prove expensive to run in practice. With data analysis increasingly done in the cloud, where we pay for the use of computing and storage, we may find that some changes make the model slightly less accurate but cheaper to run. A data engineer can also help with that, but the trade-off between accuracy and cost can be a tricky choice.
The business side of data science
I've described a basic outline of the data science process. As you can see, there are some elements that we can call engineering, or even an art. We also need to bear in mind that in the commercial world, data science is a business. That is to say, the purpose of our experiments and the success of the process will always be most usefully focused on straightforward commercial realities.
As a result, data science is generally more collaborative than you might think. It isn't an isolated, technically obscure discipline, with data scientists working alone in the lab. At its best, data science involves widespread collaboration across business and IT domains and adds new value to many different facets of an organization's work.