
You can more - Fotolia
Prepare for an AWS outage with these preventative steps
Set up the proper data protection and recovery measures before a cloud outage hits. Follow these backup and disaster recovery tips to keep workloads running during and after an outage.

Cloud outages are a matter of when, not if, so organizations must be prepared.
Public clouds and the applications hosted on them can fail in many ways, such as data center outages, service-level disruptions or various kinds of malicious attacks on cloud infrastructure. And despite the resiliency of the AWS cloud, it's still occasionally hit with downtime, such as the 2019 outages in its U.S.-East-1 and Frankfurt regions, which caused some customers data losses.
IT teams can take many steps to prepare for AWS outages. At the very least, they should keep backup copies of mission-critical data and store them in multiple regions, other clouds or private infrastructure as part of a hybrid or multi-cloud architecture.
And while a simple backup can reduce an outage's impact, other steps are required to ensure applications keep running in the face of an outage. Let's review some of the steps organizations should take to prepare for an AWS outage or application failure.
Start with high availability
IT teams need to decide how much redundancy they want to bake into their workloads to ensure the desired level of availability. Start by selecting a storage class with high availability. This will provide data mirroring across multiple sites in the same region.
"Resiliency and disaster preparedness require that there is more than a single instance of critical data, no matter who the provider is and how good their track record," said Todd Traver, vice president of IT optimization and strategy at Uptime Institute, an IT advisory organization.
AWS has multiple storage tiers with varying degrees of availability. Developers can also use a range of other services to help reduce the effects of individual VM outages on AWS. For example, Amazon Route 53 can help address DNS problems, while Elastic Load Balancing and AWS Auto Scaling can help protect against instance failures.
In some cases, individual data centers within the same availability zone are separated by 60 miles or less to ensure synchronous low-latency connections. While this option protects against outages caused by an individual data center or single database instance failures, it won't necessarily protect against an incident that impacts closely coupled data centers. This could include weather events such as hurricane-related flooding or wind damage that cause power and network outages. For example, in 2012, Hurricane Sandy impacted many regional data centers in the New York area.
Most cloud providers offer out-of-region failover options that connect data centers many miles apart to eliminate the risk from a single region impact. For example, AWS users can replicate data across AWS Regions by using private, high speed networking and public internet connections. But these multi-region setups come with potential trade-offs since the data centers are too distant for low-latency synchronization, Traver said.
Assess data protection requirements
To prepare for a cloud outage, ensure your enterprise's business and technical requirements are aligned. Evaluate, rationalize and categorize the data protection, availability and retention periods for each datastore that resides in the cloud, said Traver. Then, establish rules that define the data handling characteristics based on this categorization. These characteristics can be translated into requirements for the physical site, the local geography and the mirroring policies.
Traver also recommends enterprises formally evaluate and document their data handling requirements by working with various end users in the business that could be impacted by cloud outages. These business requirements need to be translated into verified technical requirements in terms of cloud providers, network providers and physical locations. For example, AWS users can utilize Amazon Simple Queue Service so instances can scale independently as needed, based on the length of the queue. If an outage were to occur, a new instance would pick up queued requests when your application recovers.
Establish resiliency metrics
It's impossible to determine every possible way the cloud can fail. But the worst failures are usually the result of partially failed applications, so organization should create a roadmap that specifies the immediate steps to take when an AWS outage occurs, said Marty Puranik, president and CEO of Atlantic.Net, a cloud consultancy.
"All companies should at least contemplate outages and their business processes for dealing with them before they happen," Puranik said.
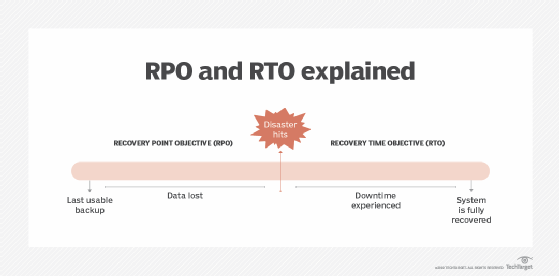
Cloud managers should have a disaster recovery backup plan or service ready to go, Puranik said. This plan should include metrics like a recovery point objective (RPO) and a recovery time objective (RTO). An RPO defines an accepted amount of downtime for a workload. A longer RPO requires fewer updates and is easier and cheaper to maintain, but it could result in more data loss in an extended outage. An RTO characterizes how quickly a backup can be spun up in response to failures. An organization's disaster recovery plan should meet its RPO and RTO objectives. This will vary depending on the hosted application.
Rehearse for AWS cloud outages
Databases aren't the only type of data vulnerable to an outage. Application state, configuration settings or application logs can also be lost in an outage. It's important to ensure that an enterprise can restore these data types as well.
"There is a common misconception that everything in the cloud is already backed up without any intervention, but it is not," said Brian Bullock, core infrastructure engineer consultant at Sparkhound, a digital advisory service.
And while IT teams should plan for high availability, that doesn't completely protect data from being deleted or hit by ransomware. Companies should rehearse a recovery from multiple failure scenarios, including public cloud outages, ransomware attacks or natural disasters, Bullock said.
And while many companies adopt a hybrid cloud model to prepare for an outage, this move is only useful if a hybrid cloud is already part of the company's strategy, Bullock said. If not, opt for a multi-region or multi-cloud strategy, since scaling and elasticity can become an issue when dealing with on-premises hardware, Bullock said.
Dig Deeper on AWS infrastructure
-
![]()
AWS apologises for 14-hour outage and sets out causes of US datacentre region downtime
By: Caroline Donnelly
-
![]()
AWS cloud outage reveals vendor concentration risk
By: Sean Kerner
-
![]()
Government faces questions about why US AWS outage disrupted UK tax office and banking firms
By: Caroline Donnelly
-
![]()
AWS confirms it is working to 'fully restore' services after major outage
By: Caroline Donnelly



