
kentoh - Fotolia
How Amazon Comprehend works for basic text analysis
Amazon's text analysis service, Comprehend, parses documents for key phrases, sentiment and more. But there are volume and input limitations to mind.

Amazon continues to unveil AI tools designed to simplify everyday business tasks, and its Comprehend service looks to fit that bill.
Amazon Comprehend is a natural language processing service that enables developers to quickly analyze a text document. The service uses machine learning to extract and classify parts of the text, called entities, into fields such as organizations, locations, people and dates. Comprehend also uses advanced AI algorithms to extract key phrases and rank them with a confidence score on how important that phrase is to the overall document. These key phrases can help categorize a document or identify language patterns in a group of documents.
Developers can test Amazon Comprehend via AWS Management Console. They can enter unstructured text into the dashboard's input box, which can be useful to test how different types of text input affect application output. The service provides automatic language detection, or developers can manually specify a language. The console can display output in a list format, a more graphical title format or the JSON format returned from an API call.
While it might be helpful to run text documents through the console for testing, this isn't applicable for real-world applications. To integrate with applications in real time, AWS provides a simple API accessible via any of the supported software development kits, including the AWS SDK for JavaScript in Node.js.
Use batches for multiple docs
In the API, developers can detect a document's dominant language, entities, key phrases or overall sentiment. Additionally, developers can submit a batch job to achieve better performance and gather analytics on a set of documents. Batches can also determine correlation of key phrases in documents, rather than indicate what might be important in just one document.
Developers can choose to asynchronously execute detection on a large batch of documents at once and then poll for responses later. This is helpful when you need to run Comprehend on a large backlog of documents, such as an archive of all blog posts from before 2017. As long as it's not a time-sensitive request, it's significantly more efficient and cost-effective to issue a batch request than to pull down real-time analytics for each individual job.
Go beyond the keyword
Let's use an example text phrase to help us understand the service: "I ate an apple this morning before going to work at Microsoft." If you work on a stock ticker app and you want to see stories related to Apple, the technology company, a simple search for "apple" in any traditional full-text indexing system might result in our example phrase, which is completely unrelated to Apple. But when we run this phrase through Amazon Comprehend, we can see slightly different results.
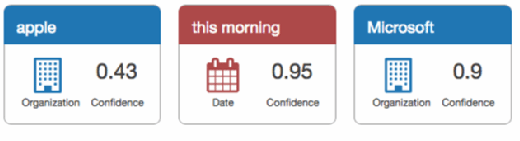
While Comprehend picks up that Apple might be an organization in this sentence, it lists a confidence score of 0.43. Typically, anything below a 0.8 is safe to exclude, so your application could classify this story under Microsoft, but not for an Apple Inc. match.
Speak my language
As of its initial launch, Amazon Comprehend only supports English and Spanish. When using the API, users must specify the input language to use any API except the language detection one. To mimic what the console provides, users can first execute the detectDominateLanguage API and then pass that output along to other APIs, such as detectEntities:
const language_response = await comprehend.detectDominantLanguage({
Text: document_text}).promise();
// Fetch the highest confidence language
let language = 'en';
let confidence = 0;
for(let guess of language_response){
if(guess.Score > confidence){
confidence = guess.Score;
language = guess.LanguageCode;
}
}
const entity_response = await comprehend.detectEntities({
Text: document_text,
LanguageCode: language}).promise();
for(let entity of entity_response.Entities){
// Only show items with a high confidence
if(entity.Score > 0.8){
console.log(entity.Type, entity.Score, entity.Text);
}
}
The code above will first identify what language this text document most likely contains and then run the detectEntities API. If you already know the primary language for the documents, you can skip this step.
Analyze text sentiment, phrases
Amazon Comprehend can also identify the overall sentiment of a text document and return sentiment analysis in these categories: Positive, Negative, Neutral or Mixed. The service ranks each possible value with a confidence score in the same way it does with entities. This sentiment analysis, as an example, can help companies weed out Positive and Negative text about their products on social media.
Key Phrases can help an IT team build a phrase cloud to determine the most common user talking points about a particular topic. This differs from normal word clouds, as a phrase could contain multiple words for a term like Amazon Web Services. Additionally, Key Phrases only identify phrases that are related and important to a topic, so if an innocuous phrase is mentioned but it isn't relevant to the overall article, it will have a lower confidence score.
Comprehend's constraints
In addition to its support for only English and Spanish, developers must input data to Comprehend as plain text; HTML isn't supported. This means you can't simply scrape an entire website and try to run Comprehend on it.
Additionally, the service imposes a limit of 5 KB, and the content must be encoded with UTF-8. Comprehend only enables 25 documents per batch detection request, although asynchronous detection jobs can send up to 50,000 files or 1 GB in total -- as long as no single document exceeds 2 MB.
Amazon Comprehend appeals to a very specific market. Organizations that want to perform simple text analysis on unstructured content can use Comprehend to add a little bit of AI into any application.






