
Getty Images
The basics, benefits and risks of cell-based architecture
Cell-based architecture adds a new twist to enterprise infrastructure by speeding deploys, improving uptime and maybe even reducing the test effort.

Classic failover strategies, such as reverting to backup databases or servers, are expensive to design, test and maintain -- but so are cascading failures that can bring down entire systems.
Cell-based architecture (CBA) design is an emergent approach aimed at remedying this issue by eliminating single points of failure. Companies like Slack and products like Amazon's Prime Video have already migrated to a cellular approach in response to outage incidents and increased traffic and data demands. But each architectural decision comes with tradeoffs, so it's important to weigh the advantages of high availability and scalability with the complexity and costs that a cell-based approach can bring to large application systems.
The basics of cell-based architecture
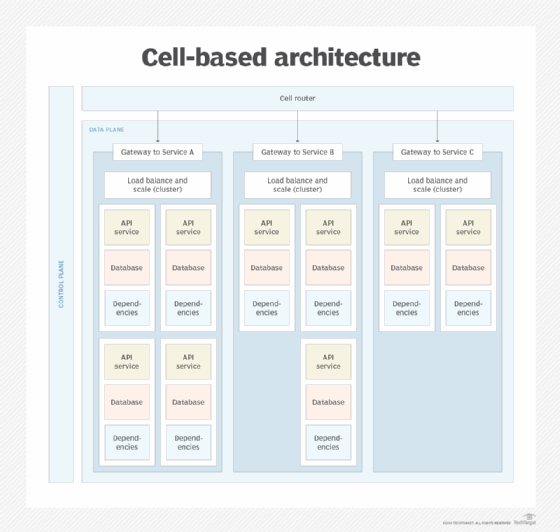
CBA decomposes a software system into large collections of partial or complete copies of the system's various application services and data components. In the case of microservices-based applications, each cell encompasses one or more microservices that operate in accordance with defined business logic.
A cell is an isolated, independent unit of a software system. The cell contains a set of services that make logical sense to connect. A profile, for example, could be stored in a database and have related create, edit and read services. Cells also contain all the dependencies they need to make the services run, such as the databases with the user information in those profiles.
Cells need to be backed up, deployed and created separately. They have one access point for data to enter and leave, typically a gateway like the API gateway pattern. Because a cell is independent and contains everything needed to deploy a service, it can be duplicated and reused during times of peak demand. The routing layer can reroute traffic to new cells to cover the load and includes the following:
- Control plane to provide the administrative APIs to provision and update cells.
- Data plane to forward traffic.
- Management plane for configuration and monitoring.
The routing layer can also include a load balancer, which works in conjunction with the management plane to observe heavy loads or replace systems that are no longer operating.
Key features and design of cell-based architecture
The management and routing isolation features of a cell-based approach work together to create new possibilities. For example, multiple redundant cells can enable high availability, segregating data across geographic regions or availability zones (AZs). A large enterprise might place cells in different regions of a public cloud to provide customers with faster responses. In terms of resiliency, the load balancer and management plane can maintain a service even when a cell is lost. The independent nature of the cells can also keep the application up when another service goes down.
The most common executions of cell-based architecture integrate cloud computing and autoscaling, where a cell typically implements one or more RESTful services. Yet, there are other ways to construct a cell-based architecture. Cells can exist on separately running physical servers or virtual servers on the same machine using routers, firewalls and IP security to segregate an existing network. Alternatively, cells could also live on the same machine and use different permissions, processes or user IDs to achieve isolation. These examples demonstrate how cell-based architecture is a pattern, one that offers versatile methods for cell segregation. Companies using microservices or Kubernetes may find what they are already doing is close to a cell-based approach.
Benefits of cell-based architecture
Cell-based architecture provides a vision for building large, highly reliable applications with several key advantages. Some significant benefits are the following:
- Isolated failure. Because data storage is separate, an individual crash or memory error only takes down a single element. It also means an organization can spend more resources on redundancy for essential services, such as authentication, ad serving or path to purchase, and less on noncore services.
- Isolated testing. Cells are autonomous and have separate responsibilities, so they are easy to recreate for testing. A defect introduced in one cell is unlikely to impact others. Further, the separate testing and deployment of cells do not necessarily require extensive regression testing of the system. CI/CD tools and platforms, like Docker and Kubernetes, make exporting, importing, loading and running a cell a matter of a few keystrokes and enable the creation of a different deploy pipeline for each cell.
- Less downtime. Due to cell redundancy, the load balancer can redirect traffic when one cell is out, resulting in near-zero downtime.
- Scalability. As demand increases, an organization can either create redundant cells and load balance them or split cells. If a cell does not contain any data -- it might just access other APIs, for example -- the management layer can create a new cell and balance the load between them. If a cell does contain data, it might be possible to segregate the data and route it or implement a write-through cache.
- Separated rollouts. Cells can roll into production separately, each on its own CI/CD pipeline. This independence enables CD.
Risks of cell-based architecture
Before implementing a cell-based architecture, it is important to consider the challenges that arise from adding yet another layer of infrastructure. Here are a few things to expect:
- Complexity. Cell-based work requires more bandwidth, processing power, memory and interprocess communication. Debugging is difficult unless you add an observability layer that keeps logs in a separate cell but can double the bandwidth requirement.
- Cost. An observability layer creates vast increases in data storage costs, and the CPU and memory costs also increase cloud compute spend. Beyond that, the architecture may require an entirely new team for development -- and another for support.
- Lack of discipline. Migrating to a cell-based architecture requires vision, discipline and excellent communication. Without a prime mover, an organization might not achieve the needed isolation by true cell-based architecture and thus not get the benefits.
- System failure. Documented successes with cell-based architecture are generally achieved by new systems, not conversions from legacy systems. Without proper performance testing at scale, a conversion to a cell-based approach might create a hard-to-recover system failure.
When to use cell-based architecture
The concept of a cell-based architecture originally emerged as a way to address cascading errors and failover problems within complex application systems. Systems that run at a global or internet scale are especially good candidates for cell-based architecture, as sheer scale requires redundancy and scalability.
Cell-based architecture is a natural fit for organizations looking to align business services with the internet services they expose -- and to build and deploy web services in the cloud. Setting up the components and CI/CD pipeline might create a fair amount of work at the outset. As an organization grows, the separation of concerns can accelerate the development of new cells and ensure deployments remain clean and simple.
For growing organizations, moving to a cellular structure requires a cleanup of backdoors, side checks, redundancies and hand-rolled SQL in order to get past a legacy big ball of mud architecture. While teams may still contend with residual issues within cells, they have full authority to fix them.
Examples of a cell-based architecture
Amazon uses cell-based architecture to deliver videos with Prime Video, enabling it to adjust cell routing to ensure load balancing, create new cells when demand is high and take a cell that is underperforming out of rotation. Cells serve up video and don't have a state, so if one gets stuck in an infinite loop, the system automatically detects and reroutes traffic, shuts the cell down and creates a new one.
Slack migrated to a cell-based architecture after an incident involving a service outage in 2021. Slack decided to treat the AZs, which can have outages, as cells and build software to enable failover and routing when a cell goes down. To do that, it had to isolate the code within each AZ, creating a silo, or, in other words, a cell. As a result, when AZs fail, Slack users should no longer see an outage.
Matt Heusser is managing director at Excelon Development, where he recruits, trains and conducts software testing and development. The initial lead organizer of the Great Lakes Software Excellence Conference and lead editor of "How to Reduce the Cost of Software Testing," Heusser served a term on the board of directors for the Association for Software Testing.







