
Getty Images/iStockphoto
Key considerations for data-intensive architectures
A shift toward data-driven decision-making amplifies the need for scalable systems that deliver real-time business insights supported by quality data.

Data-intensive architectures, built to handle large volumes of data rather than large amounts of traffic, play a critical role in conceptualizing systems that can help businesses manage and process massive data inflows.
The varied considerations for these architectures can involve the following:
- Handling data volumes.
- Archiving historical data.
- Managing data quality.
- Identifying data drift that might arise from quality issues or pattern changes, such as consumer behavior.
- Generating cost-effective business insights.
Processing vast amounts of data is often expensive but not always inherently valuable. Compare data-intensive systems to transaction-intensive architectures and explore data-intensive patterns for designing and managing an architecture that delivers value while balancing cost and ROI in proportion to data size.
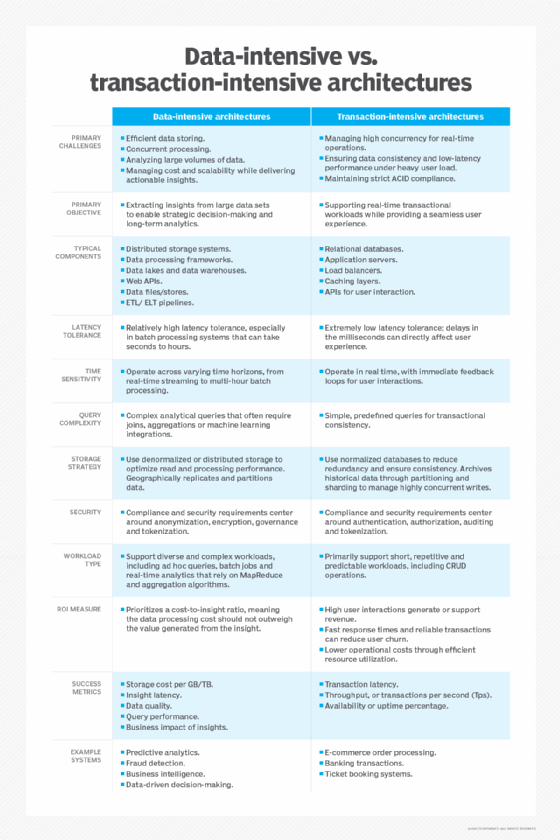
Data-intensive vs. transaction-intensive architectures
The distinction between data-intensive and transaction-intensive applications lies in their purpose, design principles and operational goals. The following table outlines key differences between the two architectures.
Key considerations for data-intensive architecture patterns
Established data-intensive architecture patterns can address distinct data collection and processing problems in large-scale systems. As businesses consider these patterns, constraints such as processing costs, storage costs and time to insight can significantly influence a platform's ROI.
An efficient data-intensive architecture can help organizations reduce unnecessary expenses and maximize actionable value. However, it's important to focus on how the infrastructure can support business objectives and ROI rather than getting lost in raw data metrics. The following architectural patterns for data-intensive applications are listed alphabetically and offer efficiency, flexibility and resource usage tradeoffs.
Command query responsibility segregation (CQRS)
Using CQRS to separate read/write data models can improve scalability and data management capabilities for systems that exhibit significant disparities between read/write volumes. However, it does rely on eventual consistency. In constructing data models specifically for a read or a write concern, it's essential to maintain an async data flow between models.
Data mesh
A data mesh aims to solve challenges around data governance, data discovery, lineage and reuse within an organization. It separates a data platform's foundational components and makes data available as a distinct product across the organization. Ownership is distributed and decentralized, but a steering group manages supporting components and conventions. These conventions can help ensure that governance, lineage and discovery are consistently implemented across domains. A data mesh enables larger organizations, typically split into autonomous divisions, to scale more efficiently and accommodate data volumes that might be too large and fragmented for a single data lake.
Data vaults
In contrast to the data mesh approach, data vaults are a method for designing data warehouses and centralizing storage. The architecture has different storage layers that separate raw data from business insights, along with a presentation layer. Three primary components of a data vault include the following:
- Hubs, or unique business entities.
- Links or relationships between hubs.
- Satellites, or metadata and contextual attributes for hubs or links.
As one of the more common patterns, the initial implementation is generally straightforward. However, the processing and repeated enrichment of data for different uses can overgrow the system, making it complex to manage and evolve.
Kappa architecture
The Kappa architecture treats data as continuous event streams by constructing a processing pipeline that can yield data-driven insights in near real time using tools like Apache Kafka or Flink. Events are replayable and can be reprocessed as needed. This pattern is ideal for environments where real-time insights are critical to business operations, such as app-based rideshare services.
Lambda architecture
Lambda architectures typically separate data into the following three layers:
- Batch layer for historical data processing.
- Speed layer for real-time data processing.
- Serving layer that combines batch and stream processing.
The serving layer provides a unified view of all current and available data, enabling ad hoc querying and organized insights. Although a Lambda architecture is typically more expensive and complex than the other patterns mentioned in this article, it's a practical choice for applications that require a combination of real-time and historical data analytics, such as those designed for fraud detection.
Medallion architecture
Complementary to other data processing architectures, the Medallion pattern organizes data into distinct layers, refining and improving data quality and its overall structure as it transitions between them. Typically divided into landing zones, processing zones and aggregation zones -- or bronze, silver and gold -- this pattern can apply to streaming architectures and batch processing.
Priyank Gupta is a polyglot technologist who is well-versed in the craft of building distributed systems that operate at scale. He is an active open source contributor and speaker who loves to solve a difficult business challenge using technology at scale.
Dig Deeper on Enterprise architecture management
-
![]()
GreenOps: From cloud spend to carbon spend, should sustainability drive SaaS decisions?
By: Adrian Bridgwater
-
![]()
Why Apache Kafka is the AI workflow you (probably) already have
By: Adrian Bridgwater
-
![]()
End-to-end network observability for AI workloads
By: Verlaine Muhungu
-
![]()
A path to better data engineering
By: Cliff Saran



