
Getty Images
Harnessing space-based architecture for high performance
Space-based architecture offers the modularity of a distributed microservices architecture but with submillisecond data access times. Unsurprisingly, it comes with tradeoffs.

Technology's seamless integration into every aspect of daily life fuels a massive flow of data that is continuously captured, surveilled and transformed into valuable insights.
Organizations can use this information to better understand user behavior and inform business decisions, but it requires modern technology platforms that can process immense volumes of data, often in near real time.
Space-based architecture (SBA) enables low latency and high-throughput processing by trading off data consistency. When used appropriately, this specialized software architecture can present significant benefits for data-intensive systems.
What is space-based architecture?
Deriving its name from tuple space, space-based architecture uses in-memory data grids shared among stateless processing units to provide scalability, resilience and elasticity in a distributed system. Unlike typical persistent storage structures, the data grids are memory-backed and offer extremely fast read/write times across multiple nodes. Read requests are executed in memory for low-latency responses, while writes are often passed through to persistent stores for better data guarantees.
The grids are effectively a highly distributed cache backed by a persistent store. Underneath the in-memory data grids, the architecture addresses issues around initialization and cold starts by preemptively loading data from persistent stores. Taken together, SBA delivers fast data reads and writes at scale in exchange for data consistency and recency.
Components of space-based architecture
A space-based system consists of the following components, each with well-defined responsibilities.
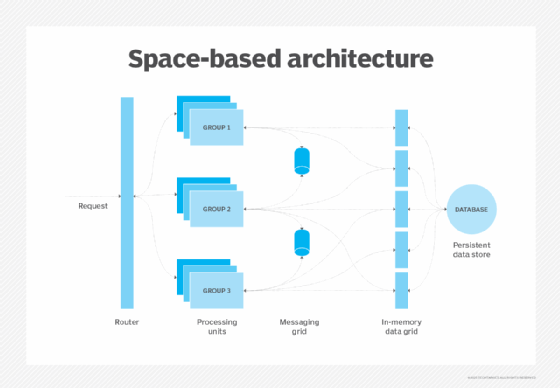
Processing units
Processing units are stateless components that execute business logic and independently handle incoming requests. Typically configured behind a load balancer to allow for horizontal scaling, the units pull data from the in-memory data grids and publish results back to the grid. Each unit is deployed across multiple nodes, breaking down a larger domain into collaborating boundaries using domain-driven design techniques.
In-memory data grid
A distributed and replicated in-memory data grid acts as the central backbone for many space-based architectures, storing working data for processing units.
Data grids can have varying capabilities depending on the tooling, setup and configuration. A typical installation offers choices around durability, scalability and versatility and should align with the needs of a system. Key considerations for configuration include the following:
- Backing by persistent stores. Data grids are often backed by a persistent data store for durability and data synchronization. Persistent stores support write-through or fire-and-forget write modes. And while data writers can write to these stores, it's typically more expensive than fire-and-forget writes. Proactively loading data into the grid can solve the cold start problem during initialization, to prevent slow queries and improve system throughput at bootup time.
- Replication and partitioning. Data grids support replication and partitioning, enabling high availability. Replication ensures data is stored redundantly across nodes in case of failure, while partitions distribute data to manage load. Examples of data platform options include Hazelcast, Apache Ignite and Redis.
- Configurable data readers and writers. Data writers and readers can write through the data grid, typically operating on primary partitions. In the absence of a primary partition, a data reader can read from a secondary partition, but it sacrifices data consistency. Secondary partitions are also useful for rebuilding primary partitions quickly.
Messaging grid
Messaging grids enable intercomponent communication and allow events to propagate through the system. Consuming and publishing events in real time ensures high throughput while maintaining modularity and loose coupling.
Routers
Routers serve as the first interception point for requests and intelligently distribute them across processing units for better scalability.
Strengths of space-based architecture
Space-based systems are ideal for high-traffic, low-latency environments, real-time stream processing, clickstream analytics and high transaction volumes due to the following architectural advantages.
High-performance data access
Memory-backed data grids facilitate significantly faster read/write when compared to traditional architectures. The architecture also allows for data storage scaling and load distribution, making it suitable for systems requiring rapid data access or those dealing with read-heavy operations.
Linear scalability and elasticity
Stateless routers and processing units can dynamically adapt in response to load variations, supporting scalability and elasticity. Data storage partitioning supports the efficient management of high transaction volumes.
Fault tolerance and high availability
Redundancy is at the core of space-based systems. When a primary partition fails, a secondary partition takes over. In the event of a complete data grid loss, the persistent data store can reinitialize the system, making it a reliable, fault-tolerant and highly available architecture.
Challenges and limitations of space-based architecture
Space-based architectures are technically complex designs to architect and manage. It's important to consider the tradeoffs that come with implementation.
Data consistency
Despite low latency access, data partitions and writes might not always be consistent. Inconsistency could trigger unexpected system behaviors and be particularly problematic for environments that expect a high degree of data consistency.
Higher storage cost
Space-based architecture stores data twice, first in memory and then in persisted stores. Duplication can lead to increased storage costs in comparison to conventional distributed architectures. Partitioning and redundancy also add complexity to the system and will likely require more development, hosting and maintenance costs.
Data loss risk
Because an in-memory grid-based system backs the primary data store, a space-based application faces the risk of data loss if a data sync fails. This possibility necessitates pass-through configuration for write management, reducing write speed or a tolerance for data loss in catastrophic failure scenarios.
Testability and Debuggability
Distributed platforms can face challenges arising from errors or failure, contributing to longer maturity cycles and data replication delays. Debugging and resolving issues become harder, requiring consideration of dependent data availability in the system design.
Longer initialization times
Initialization of caches and loading large amounts of data from persisted stores can lead to long read I/O overheads, resulting in a delayed start for the overall platform until the data load completes or achieves optimal performance.
When to use space-based architecture
Space-based architecture might not be a suitable choice for platforms that require hard data consistency, complex joining and querying systems or write-heavy systems with low read requirements, as its benefits quickly dissipate in these types of environments.
However, SBA's speed and availability make it an appropriate option for data-intensive systems such as social media, gaming and ad-tech platforms, content delivery networks, real-time analytics, fraud detection systems, sensor data streaming and financial trading.
Priyank Gupta is a polyglot technologist who is well versed with the craft of building distributed systems that operate at scale. He is an active open source contributor and speaker who loves to solve a difficult business challenge using technology.






