
Fotolia
Fundamental patterns for service discovery in microservices
Service discovery is a huge part of managing a microservices-based application. We examine helpful service discovery patterns developers can use for clean service interaction.

Microservices architecture is best suited for long-running, complex applications that have significant resource and management demands. A microservices-based application has a conglomeration of several services that can work together for better scalability, easier maintenance and seamless deployment.
To run efficiently, services need to locate one another on a network to process requests. This is where service discovery in microservices comes in.
Why do we need service discovery in microservices?
When working on microservices-based applications, you might need to change the number of microservice instances at runtime depending on the load on your service -- autoscaling, failures and service upgrades can change the amount. You must ensure that the dependent services are aware of these instances.
The number of instances of a microservice can vary. If these microservices are residing on physical servers that your team has access to, you can use a configuration file to ensure that other services know the amount of services that exist at any given time. But in cloud, it can be difficult to keep track of the number of services because of possible dynamic network locations.
Service discovery in microservices helps these service instances adapt and distribute the load between the microservices accordingly.
There are three components of service discovery:
- Service provider: Provides services over a network.
- Service registry: A database that contains the locations of available service instances.
- Service consumer: Retrieves the location of the service provider from the service registry and then talks to the service instance.
Data residing in the service registry should always be up to date so that the clients -- the other microservices -- can discover the service instances at runtime. If the service registry is down, it would negatively affect both service providers and consumers. To overcome this, enterprises typically use a distributed database, such as Apache ZooKeeper, as a service registry.
Service discovery patterns
There are essentially two main service discovery patterns: client-side discovery and server-side discovery. Let's take a look at what each entails.
Client‑side discovery pattern
In this pattern, the service consumer -- also known as the service client or the client -- searches the service registry to locate a service provider, selects an appropriate and available service instance using a load balancing algorithm and then makes a request. The service instance's location is registered with the service registry at the time when the service starts. As soon as the service instance is terminated, the same information is deleted from the service registry.
This pattern is relatively easy to understand and it can easily make intelligent load-balancing decisions because the service consumer is aware of the available service instances.
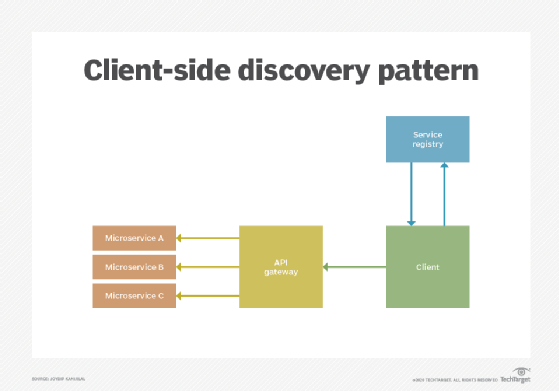
Note that in this pattern, the discovery service may or may not be placed behind an API gateway. If it isn't behind an API gateway, it's your responsibility to reimplement balancing, authentication and other cross-cutting concerns for the discovery service.
A major drawback of this pattern is that the service consumer and the service registry are tightly coupled which means you need to implement the required logic for service discovery on the client-side for each programming language you might use. Moreover, since microservices architecture is a conglomeration of disparate technologies, tools, frameworks and languages, application management become increasingly complex.
Server‑side discovery pattern
In this pattern, the client-side service consumers aren't aware of the service registry and make requests via a router. The router searches the service registry and, once the applicable service instance is found, forwards the request accordingly. The client doesn't need to bother about service discovery and load balancing, the API gateway can select the right endpoint for a client-side request.
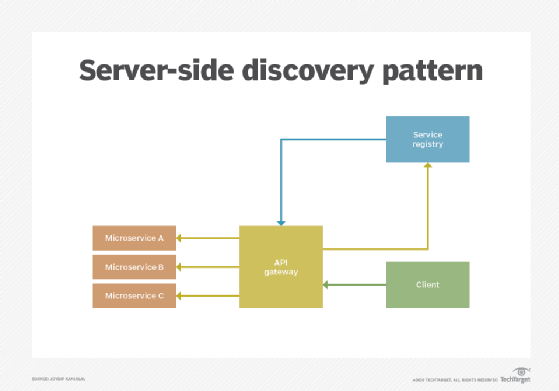
A main benefit of the server-side discovery pattern is that it is language and framework agnostic. However, the deployment environment should provide the load balancer and it should be highly available. Be sure to manage and replicate it appropriately for availability and capacity.
Service registration patterns
The service registration pattern consists of two smaller ones:
- Self-registration pattern: The service instance registers its address with the service registry, and the service deregisters itself from the registry as soon as the instance terminates.
- Third-party registration pattern: The service instances don't register or deregister themselves. Rather, the registration process is handled by a system component called the service registrar.
Keep in mind that once a service terminates, it might not deregister itself. This means that if a service consumer searches for an instance of this service in the registry, it will receive an invalid address error. To prevent this, the service provider should connect its services with the registry at regular, specified intervals of time to prove that the service is still operational. The service registry can then deregister a service if the provider has not sent a response for quite some time.







