parser

What is a parser?
In computer technology, a parser is a program that's usually part of a compiler. It receives input in the form of sequential source program instructions, interactive online commands, markup tags or some other defined interface.
Parsers break the input they get into parts such as the nouns (objects), verbs (methods), and their attributes or options. These are then managed by other programming, such as other components in a compiler. A parser may also check to ensure that all the necessary input has been provided.
How does parsing work?
A parser is a program that is part of the compiler, and parsing is part of the compiling process. Parsing happens during the analysis stage of compilation.
In parsing, code is taken from the preprocessor, broken into smaller pieces and analyzed so other software can understand it. The parser does this by building a data structure out of the pieces of input.
More specifically, a person writes code in a human-readable language like C++ or Java and saves it as a series of text files. The parser takes those text files as input and breaks them down so they can be translated on the target platform.
The parser consists of three components, each of which handles a different stage of the parsing process. The three stages are:

Stage 1: Lexical analysis
A lexical analyzer -- or scanner -- takes code from the preprocessor and breaks it into smaller pieces. It groups the input code into sequences of characters called lexemes, each of which corresponds to a token. Tokens are units of grammar in the programming language that the compiler understands.
Lexical analyzers also remove white space characters, comments and errors from the input.
Stage 2: Syntactic analysis
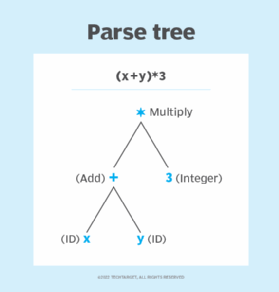
This stage of parsing checks the syntactical structure of the input, using a data structure called a parse tree or derivation tree. A syntax analyzer uses tokens to construct a parse tree that combines the predefined grammar of the programming language with the tokens of the input string. The syntactic analyzer reports a syntax error if the syntax is incorrect.
Stage 3: Semantic analysis
Semantic analysis verifies the parse tree against a symbol table and determines whether it is semantically consistent. This process is also known as context sensitive analysis. It includes data type checking, label checking and flow control checking.
If the code provided is this:
float a = 30.2; float b = a*20
then the analyzer will treat 20 as 20.0 before performing the operation.
Some sources refer only to the syntactic analysis stage as parsing because it generates the parse tree. They leave out lexical and semantic analysis.

What are the main types of parsers?
When a software language is created, its creators must specify a set of rules. These rules provide the grammar needed to construct valid statements in the language.
The following is a set of grammatical rules for a simple fictional language that only contains a few words:
<sentence> ::= <subject> <verb> <object>
<subject> ::= <article> <noun>
<article> ::= the | a
<noun> ::= dog | cat | person
<verb> ::= pets | fed
<object> ::= <article> <noun>
In this language, a sentence must contain a subject, verb and noun in that order, and specific words are matched to the parts of speech. A subject is an article followed by a noun. A noun can be one of the following three words: dog, cat or person. And a verb can only be pets or fed.
Parsing checks a statement that a user provides as input against these rules to prove that the statement is valid. Different parsing algorithms check in different orders. There are two main types of parsers:
- Top-down parsers. These start with a rule at the top, such as <sentence> ::= <subject> <verb> <object>. Given the input string "The person fed a cat," the parser would look at the first rule, and work its way down all the rules checking to make sure they are correct. In this case, the first word is a <subject>, it follows the subject rule, and the parser will continue reading the sentence looking for a <verb>.
- Bottom-up parsers. These start with the rule at the bottom. In this case, the parser would look for an <object> first, then look for a <verb> next and so on.
More simply put, top-down parsers begin their work at the start symbol of the grammar at the top of the parse tree. They then work their way down from the rule to the sentence. Bottom-up parsers work their way up from the sentence to the rule.
Beyond these types, it's important to know the two types of derivation. Derivation is the order in which the grammar reconciles the input string. They are:
- LL parsers. These parse input from left to right using leftmost derivation to match the rules in the grammar to the input. This process derives a string that validates the input by expanding the leftmost element of the parse tree.
- LR parsers. These parse input from left to right using rightmost derivation. This process derives a string by expanding the rightmost element of the parse tree.
In addition, there are other types of parsers, including the following:
- Recursive descent parsers. Recursive descent parsers backtrack after each decision point to double-check accuracy. Recursive descent parsers use top-down parsing.
- Earley parsers. These parse all context-free grammars, unlike LL and LR parsers. Most real-world programming languages do not use context-free grammars.
- Shift-reduce parsers. These shift and reduce an input string. At each stage in the string, they reduce the word to a grammar rule. This approach reduces the string until it has been completely checked.
What technologies use parsing?
Parsers are used when there is a need to represent input data from source code abstractly as a data structure so that it can be checked for the correct syntax. Coding languages and other technologies use parsing of some type for this purpose.
Technologies that use parsing to check code inputs include the following:
Programming languages. Parsers are used in all high-level programming languages, including the following:
- C++
- Extensible Markup Language or XML
- Hypertext Markup Language or HTML
- Hypertext Preprocessor or PHP
- Java
- JavaScript
- JavaScript Object Notation or JSON
- Perl
- Python
Database languages. Database languages such as Structured Query Language also use parsers.
Protocols. Protocols like the Hypertext Transfer Protocol and internet remote function calls use parsers.
Parser generator. Parser generators take grammar as input and generate source code, which is parsing in reverse. They construct parsers from regular expressions, which are special strings used to manage and match patterns in text.
Parsing is a fundamental concept of software development and computing theory. However, most IT pros can get by without an in-depth understanding of parsing by using low-code platforms that let users create software programs without writing thousands of lines of code. Learn the pros and cons of using low-code platforms in the enterprise.







