
Getty Images
The importance and limitations of open source AI models
Despite rising interest in more transparent, accessible AI, a scarcity of public training data and compute infrastructure presents significant hurdles for open source AI projects.

Because AI models differ in some key respects from other types of software, applying open source concepts and practices to AI models isn't always a straightforward task. It's one thing to create open source code; it's another to actually train and deploy an AI model.
Some of the most popular AI engines, such as the GPT model series underlying OpenAI's ChatGPT, have recently come under fire for being proprietary technology that operates as a black box. Amid these debates and the costs associated with proprietary AI, there is growing interest in open source AI models, which promise greater transparency and flexibility.
What is an open source AI model?
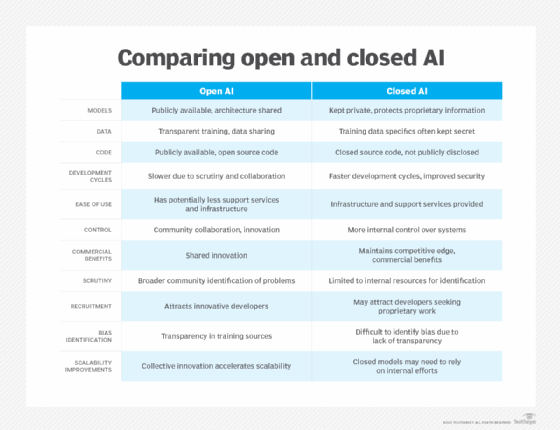
Anyone can freely access, modify and share the source code for open source software. In contrast, the source code for closed-source software -- also known as proprietary software -- is private, and only the original creators can alter and distribute it.
Similarly, an open source AI model is one whose source code is publicly available, meaning that anyone can download, view and modify the raw code that powers the model's algorithms. This accessibility ensures a level of transparency and customizability that closed-source models lack.
Many of today's best-known generative AI tools, including ChatGPT and Midjourney, are closed source, but there is also a growing open source generative AI ecosystem. Popular open source large language models available today include Meta's Llama models and models from French startup Mistral AI.
Challenges in developing open source AI models
The source code that powers an AI model is similar in many ways to the source code for any other algorithm or application. AI models can be built in any programming language, using the same development processes as for standard applications. In this sense, creating an open source AI model is straightforward.
Where matters get tricky for open source AI developers, however, is the model training stage. Training AI models requires access to vast amounts of data, and few open source AI companies or projects release that data publicly.
For example, in response to a question on a Hugging Face forum about training data for the Mistral 7B LLM, Mistral AI stated, "Unfortunately we're unable to share details about the training and the datasets (extracted from the open Web) due to the highly competitive nature of the field." In other words, the company releases its models' code, but not the data used to train those models.
This lack of publicly available training data for open source AI models creates two main challenges:
- Developers seeking to modify and retrain a model might struggle to do so. Although changing the model's source code is relatively straightforward, lack of access to the training data prevents developers from retraining their altered model on the original data set.
- Lack of transparency about a model's training data can obscure the model's operations, even when the model's source code is viewable. Because training data plays a major role in the inferences a model generates, open sourcing a model's code without also sharing the training data only provides partial transparency into the model's inner workings.
These challenges are unique to open source AI projects, as other types of applications don't require training. The need for training, coupled with the difficulty of finding publicly available open source data, is a significant technical hurdle that sets open source AI development apart from other areas of software.
The role of fine-tuning
Many open source models can be fine-tuned, which can alter how they operate. This usually involves modifying parameters and weights without fully retraining the model. Although fine-tuning offers some opportunity for customization, it's different from modifying the core code of the model itself or having complete control over the training data.
Where to get training data for open source AI
The fact that open source AI companies and projects rarely release their data sets doesn't mean that developers seeking to build, or build upon, open source AI models are totally out of luck. Those looking to develop or enhance their own AI models can acquire their own training data and retrain the model as needed.
One approach is simply to use the vast volumes of content available on the web for training purposes. This could lead to copyright challenges, however, as evidenced by recent lawsuits from content owners such as The New York Times alleging that AI developers trained on their data without permission. Plus, scraping and preparing extensive web data for training purposes is tremendously challenging; there is a massive amount of data to deduplicate, for example.
Another strategy is to use open data sets, such as those listed in this GitHub reference, which are licensed for training purposes. The drawback is that this data might not be sufficient in volume or scope for training, depending on the model's intended purpose.
The compute issue
Even when open source AI developers can obtain training data for their models, the actual training process requires enormous amounts of compute. Those resources cost money -- something that most open source projects don't have in abundance, if at all.
Some open source AI companies, including Mistral, have managed to address this problem by raising funding, which they use in part to pay for model training. But this approach might not be feasible for smaller-scale open source projects or companies that want to use open source AI, but can't justify investing large sums of cash in model training.
The future of open source AI models
In light of these challenges, developers and organizations that want to use open source AI will likely need to settle for pretrained models from companies such as Meta and Mistral for the time being. The inability to retrain those models restricts their transparency and flexibility, presenting limitations not typically encountered with other types of open source software.
This could change if organizations with deep pockets invest in creating open source data sets tailored for AI training, while also providing the compute resources necessary to perform that training. But for now, the challenges associated with model training mean that access to open source AI models doesn't typically confer all the advantages associated with other types of open source software.
Chris Tozzi is a freelance writer, research adviser, and professor of IT and society who has previously worked as a journalist and Linux systems administrator.







