Data science vs. machine learning: What's the difference?
Data science and machine learning both play crucial roles in AI, but they have some key differences. Compare the two disciplines' goals, required skills and job responsibilities.

With the recent explosive growth of artificial intelligence, two connected fields are seeing significant demand: data science and machine learning.
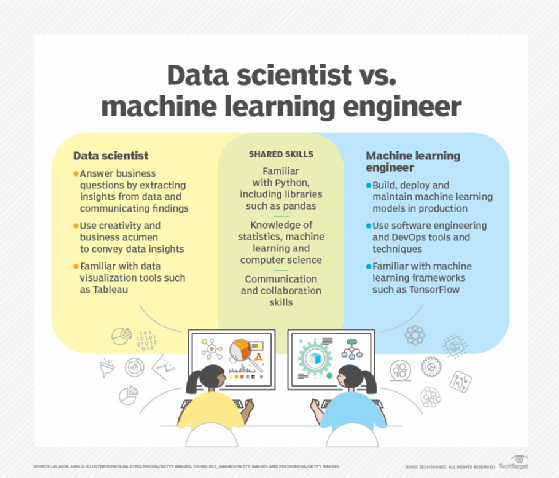
Data scientists and machine learning engineers play essential roles in building and working with AI systems and are behind some of the industry's most exciting developments. Although the two disciplines are often conflated, data science and machine learning have distinct focuses and require different skills.
For organizations developing an AI strategy, understanding these nuances is key to building effective teams. And for job seekers looking to work in the AI field, it's important to know what skills are necessary for these in-demand roles.
What is data science?
Data science is an interdisciplinary field that incorporates concepts and methods from data analytics, information science, machine learning and statistics.
Overall, data scientists aim to extract actionable insights from data to address a business or research problem. By identifying patterns and trends over time, data scientists help organizations make more informed decisions, improve efficiency and develop data-driven strategies.
Steps of the data science pipeline
Typically, a data science workflow involves the following stages:
- Hypothesis generation. Before actually collecting or analyzing any data, data scientists identify a business or research question and develop a hypothesis to test.
- Data collection. Based on the problem at hand, data scientists then obtain the necessary data from various internal or external sources.
- Data preprocessing. In this often time-consuming step, data scientists clean and prepare data for analysis, addressing issues such as inconsistent formatting and missing values.
- Exploratory data analysis. Initial analyses, such as collecting summary statistics and visualizing data with charts and heat maps, give data scientists a general sense of the overall data set and its characteristics.
- Modeling and evaluation. Data scientists then evaluate the initial hypothesis using machine learning and statistical analysis, making sure to validate generated models' reliability and accuracy.
- Reporting and visualization. Finally, data scientists convey their findings to stakeholders, such as business leaders or other technical teams, through presentations, written reports or data visualizations.
Common applications and example use cases for data science
Because data-derived insights and predictive analytics models are useful in almost any sector, data science has many possible applications across a wide range of industries.
The following are some examples of common industry use cases for data science:
- Retail. Data scientists help retailers and e-commerce companies develop targeted marketing initiatives based on customer attributes and purchasing behavior.
- Finance and banking. Data scientists develop statistical and machine learning models for financial services tasks such as fraud detection, risk assessment and portfolio optimization.
- Manufacturing. Data scientists help manufacturers optimize supply chains by forecasting demand and planning when to conduct maintenance based on predicted equipment failures.
What is machine learning?
Machine learning is both a subset of AI and a technique used in data science.
Machine learning algorithms detect patterns and relationships in data, autonomously adjusting their behavior to improve their performance over time. With enough high-quality training data, machine learning systems can make complex predictions and analyses that would be difficult or impossible to code manually.
Machine learning engineers aim to build flexible, reliable machine learning systems that can adapt to new data. This data-centric approach differentiates machine learning from traditional software. Unlike typical software programs, which have hard-coded rules, machine learning models can automatically adjust their behavior as they are exposed to new data, without needing a human developer to step in.
Steps of a machine learning pipeline
Machine learning pipelines, similar to data science workflows, start with data collection and preprocessing. The model then takes in an initial set of training data, identifies patterns and relationships in that data, and uses that information to tune internal variables called parameters. The model is then evaluated on a new set of testing data to validate its accuracy and see how it responds to previously unseen data.
All of these steps are familiar from the data science pipeline. But a data scientist's next step is typically to present the findings of their analyses to stakeholders, whereas a machine learning engineer is usually responsible for deploying, monitoring and maintaining models in production. These model deployment and monitoring stages resemble the DevOps cycle for traditional software, leading to the popularization of the term machine learning operations (MLOps).
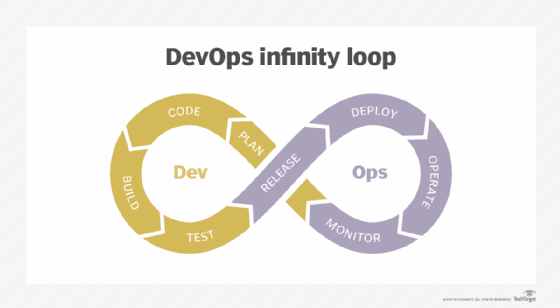
Deploying a model refers to integrating it into production applications and software, and monitoring involves tracking, debugging and maintaining the model after deployment. Because real-world environments are constantly changing, MLOps teams refine and retrain models on an ongoing basis to ensure that they continue to perform well over time.
Common applications and example use cases for machine learning
Like data science, machine learning is useful across many industries. Machine learning algorithms can perform a wide range of functions relevant to business objectives, such as prediction, workflow automation and content generation.
The following are some examples of common industry use cases for machine learning:
- Health and medicine. Machine learning can assist with healthcare-related tasks such as identifying anomalies in medical scans and predicting a patient's risk of readmission.
- Law. Machine learning can streamline the workflows of attorneys and paralegals by automating aspects of document review and generating templates for common legal documents.
- Energy. Machine learning has shown promise for a wide range of energy sector tasks, including energy consumption forecasting and predictive maintenance for infrastructure such as wind turbines.
The difference between data science and machine learning
Although data science and machine learning overlap to an extent, the two have some important differences.
The term machine learning refers to a specific subset of AI. Machine learning models are integral to many data science workflows, making machine learning a crucial piece of a data scientist's toolkit. But data science as a discipline encompasses much more than just machine learning, drawing on methodologies and ideas from statistics, information science, and even graphic design and storytelling.
Data scientists also typically don't deploy and monitor models in production. In contrast, roles in machine learning engineering and MLOps require some knowledge of data pipelines and infrastructure, as well as practices used in traditional software engineering and DevOps.
Typical data scientist salary and job demand
According to the U.S. Bureau of Labor Statistics, demand for data scientists is projected to grow by 35% this decade -- much higher than the average projected growth rate for all occupations of 5%. That works out to about 17,700 expected new data scientist roles per year.
Unsurprisingly, with their skills in such high demand, data scientists are well compensated. As of July 2024, the median salary for a mid-level data scientist in the United States is $95,800. In addition to base salary, total compensation can also include bonuses, stock options, equity and comprehensive benefits packages, especially for data scientists at large companies and tech startups.
Salary for a data scientist in 10 major U.S. cities
| City | Median base salary* |
| San Francisco | $119,750 |
| New York | $111,894 |
| Boston | $107,391 |
| Washington, D.C. | $106,625 |
| Seattle | $105,667 |
| Chicago | $100,494 |
| Denver | $97,524 |
| Austin, Texas | $91,435 |
| Atlanta | $94,842 |
| Charlotte, N.C. | $92,926 |
Skills needed to become a data scientist
Typically, a data scientist role requires an undergraduate degree in a field such as computer science, statistics or information science. Many data scientists also have master's or doctoral degrees with a focus on data science, statistics or machine learning.
Other pathways into data science include industry bootcamps and certifications. Those following this path should carefully evaluate any prospective program to ensure it is comprehensive and reliably places students into relevant jobs. Alternatively, some data scientists start out in a related role, such as data analyst or business analyst, and then upskill into a data scientist role by gaining work experience with the tools and techniques used in data science.
Where does data analytics fit in?
Data analytics is related to but distinct from both data science and machine learning. Data analysts prepare and interpret data, create visualizations and reports, and communicate their findings to stakeholders. A career in data analysis often requires experience with SQL, spreadsheets, and data visualization and reporting tools.
However, data scientists and machine learning engineers use more advanced methods and tools than data analysts. Notably, machine learning engineers and data scientists regularly work with machine learning algorithms, whereas data analysts usually don't. Data analysts also don't typically need familiarity with computer programming or data infrastructure.
Data analytics is more limited in scope than either machine learning or data science, focusing on deriving insights from existing data rather than creating predictions or maintaining deployed models. In contrast, data scientists build predictive models that can forecast future outcomes, and machine learning engineers maintain and refine a variety of models in production over time.
Technical skills
Data scientists use a range of technical methods and tools to do their work. At a high level, data science involves a combination of methods from computer programming, machine learning, statistics and data visualization.
Key technical skills for data scientists include the following:
- Familiarity with the programming languages Python and R.
- Knowledge of statistical methods and machine learning algorithms.
- Skills related to data collection, such as web scraping and working with APIs.
- Understanding of data structures and database architecture.
- Data visualization, including popular libraries and platforms such as Tableau and Matplotlib.
- Popular tools and frameworks used in data science -- for example, Jupyter notebooks, a web-based integrated development environment designed for data science workflows, and Hadoop, an open source framework for big data analytics.
Soft skills
In addition to a strong technical background, business, interpersonal and creative skills are also important for data scientists.
Although data science is a technical role, essential data science skills also include a solid understanding of business objectives. A basic understanding of business and finance can help data scientists identify business problems, understand how to interpret data in light of business metrics, and effectively communicate insights to nontechnical teams and executives.
Data scientists also need strong collaboration and communication skills. The ability to work well with technical and nontechnical teams helps data scientists plan their work effectively, keep other team members up to date on project status and outcomes, and clearly convey their findings at the end of a project.
This last responsibility also requires some creative skills, such as storytelling and design. A good data scientist knows how to craft a clear and compelling narrative, whether in the form of a presentation, visual or written report. To effectively communicate data insights, data scientists need the ability to create valuable, accessible visual and written content that's understandable to their target audience.
Typical machine learning engineer salary and job demand
Machine learning engineering is an emerging field, but demand is expected to grow over the coming decade: McKinsey's 2023 Global Survey on AI found that machine learning engineers were among the top AI-related roles organizations are hiring.
With such a booming market for AI and machine learning, it's no surprise that machine learning engineers, like data scientists, tend to be paid well. The median salary for a machine learning engineer in the United States is $106,188 as of July 2024, and total compensation often includes bonuses, stock options, equity and comprehensive benefits.
Salary for a machine learning engineer in 10 major U.S. cities
| City | Median base salary* |
| San Francisco | $132,734 |
| New York | $124,027 |
| Boston | $119,036 |
| Washington, D.C. | $118,187 |
| Seattle | $117,125 |
| Chicago | $111,391 |
| Denver | $108,099 |
| Austin, Texas | $105,126 |
| Atlanta | $103,958 |
| Charlotte, N.C. | $103,002 |
Skills needed for a career in machine learning
There are a range of potential career paths within the field of machine learning, but machine learning engineer, MLOps engineer and AI engineer are among the most common job titles. Similar to data scientists, machine learning engineers typically have at least a bachelor's degree in computer science, statistics or math, and many also have a master's or doctoral degree.
Some machine learning engineers go straight from an academic program into a machine learning engineering or MLOps role. Others start out as software engineers, data engineers or data scientists and make their way into a machine learning career by picking up hands-on experience with machine learning models and systems.
Technical skills
Day-to-day responsibilities vary across organizations and industries, but certain fundamental technical skills are applicable to most machine learning engineering jobs.
In general, machine learning engineers should have a strong background in computer science, math and statistics. Key areas that are relevant to machine learning include linear algebra, calculus, probability, data structures and optimization. Budding machine learning engineers often focus their education and early experience on a particular field -- for example, natural language processing, computer vision or reinforcement learning.
Proficiency in Python is an almost universal expectation, as Python is the dominant language used in machine learning algorithms and workflows. It's also helpful to have experience with Python frameworks and libraries often used in machine learning, such as the following:
- NumPy and pandas.
- Matplotlib and Seaborn.
- Scikit-learn.
- TensorFlow and Keras.
- PyTorch.
On the operations side, although machine learning models differ from traditional software in some important ways, MLOps and machine learning engineers should also understand software engineering and DevOps best practices. Skills like software design, testing and documentation are all useful for building reliable and maintainable machine learning systems.
Examples of software development, DevOps and IT operations tools that machine learning engineers might use include the following:
- Version control tools such as Git and GitHub.
- Continuous integration and continuous delivery (CI/CD) tools such as Jenkins and GitLab.
- Containerization tools such as Kubernetes and Docker, including Kubeflow and other machine learning plugins.
- Cloud platforms such as AWS and Microsoft Azure, including ML-focused offerings such as AWS SageMaker and Azure Machine Learning.
- MLOps-specific tools such as Neptune AI for experiment tracking and Fiddler AI for model monitoring.
In the current job market, machine learning engineers should also consider building some expertise with generative AI. For example, knowing how to fine-tune and deploy a large language model, then manage it in production -- often referred to as LLMOps -- is a valuable skill for engineers applying for roles at companies with burgeoning generative AI initiatives.
Soft skills
Machine learning might seem like an overtly technical field, but it requires several crucial soft skills, especially for those working as part of a team in production ML environments.
Machine learning engineers need to collaborate effectively with a diverse range of teams and backgrounds, including data scientists, software developers, product managers and more. This often involves clearly articulating complex technical concepts to business teams and understanding diverse viewpoints. To succeed at this type of cross-functional work, it's essential to develop strong communication and listening skills.
In addition, machine learning engineers need a combination of analytical and creative thinking abilities, as designing and managing machine learning systems in production often involves complex problem-solving. Organizational skills are also helpful for keeping track of complex long-term projects with multiple moving parts.
Finally, machine learning is a rapidly changing field, with new research and tools coming out by the day. An open mind, sense of curiosity and adaptability are essential to keep pace with this constantly changing environment.
Editor's note: This article was originally written in August 2023 and was updated by the author in July 2024 to reflect developments since the initial publication date, including revised salary information.
Lev Craig covers AI and machine learning as site editor for TechTarget Editorial's Enterprise AI site. Craig graduated from Harvard University with a bachelor's degree in English and has previously written about enterprise IT, software development and cybersecurity.







