
Getty Images
The ultimate guide to backup deduplication
Backup deduplication can reduce active storage space consumption, decrease backup job times and increase the overall efficiency of a storage infrastructure.

Many technologies help alleviate the strain of ensuring data protection and recovery, and one of the most crucial is data deduplication.
Backup administrators must satisfy many requirements. Key among them are protecting critical business data while managing storage and network costs. Redundancy is a major part of data backup, but too much redundancy can increase storage costs and complicate data management. That is where backup deduplication comes in.
Deduplication works by generating a hash of the analyzed data. Hash results are then compared with other results to determine duplicates. All but one copy of the duplicated information are removed and replaced with pointers to the single definitive data source.
With backup deduplication, duplicate data within backups is replaced with pointers to the source file.
The result can be a rather surprising amount of recovered space. Exactly how much space varies by the deduplication technique and the original data. The amount of space saved also depends heavily on what type of information users generate.
This article examines data deduplication and how it enables backup administrators to excel in their roles. It discusses various types of deduplication, benefits, drawbacks and specific techniques to help you determine how deduplication fits into your data backup structure.
Types of data deduplication
Several deduplication options are available, enabling backup admins to choose their own adventure regarding how the process is done. When deciding on a backup deduplication strategy, admins can determine how duplicate data is analyzed, when it is eliminated and where in the backup process deduplication takes place.
File-level vs. block-level deduplication
Deduplication techniques include two levels of information analysis, each providing its own benefits: file-level and block-level.
File-level deduplication evaluates complete files to search for duplicate information. Block-level deduplication divides data into blocks, then checks each block for duplicate information compared with other blocks. In both cases, pointers to a single definitive source replace duplicate information.
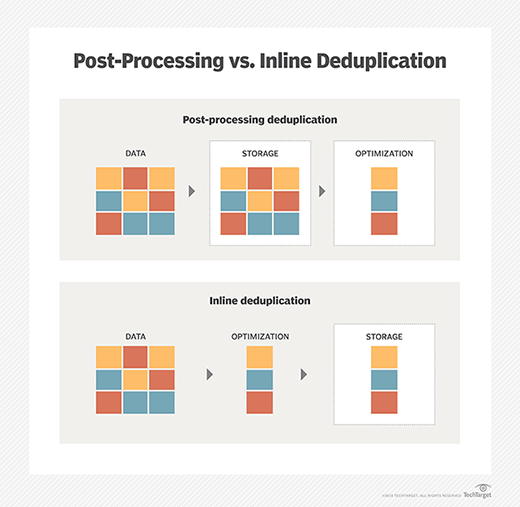
Inline vs. postprocessing deduplication
Deduplication can occur inline -- in real time -- or after a user has saved the file. Deduplication after the user has saved the file is referred to as postprocessing.
Inline deduplication can be more resource-intensive than postprocessing, slowing down the backup process. However, postprocessing deduplication requires the use of temporary storage space, while inline does not. Consider your organization's storage and processing needs to establish the best deduplication timing.
Source-based vs. target-based deduplication
Storage and backup administrators can also decide when deduplication should occur in relation to the backup process. The options are source-based deduplication or target-based deduplication.
Source-based deduplication processes information before the backup procedure begins, reducing bandwidth and storage requirements. It also has the benefit of reducing general storage requirements for the data.
Target-based deduplication processes the information at the backup target. This is a more specialized and resource-intensive approach appropriate for large data sets.
How deduplication benefits backups
Many storage administrators already use data deduplication, so backup administrators might benefit from the technology without realizing it. However, the specific benefits of data deduplication for backup administrators include the following:
- Backup job efficiency.
- Storage space optimization.
- Network bandwidth optimization.
- Increased data management efficiency.
The resulting cost reduction enables organizations to dedicate crucial financial resources elsewhere. Deduplication can also help backup admins justify retaining data longer while maintaining a smaller storage footprint on physical media.
Drawbacks of data deduplication
No technology is perfect, and data deduplication is no different. You must plan for specific issues if you implement deduplication in your environment. Potential drawbacks include the following:
- Slower system performance, particularly with the CPU. Deduplication is processor-intensive.
- Data loss risks due to hash collisions or other mistakes.
- Increased storage fragmentation resulting from the way blocks are processed and written to disk at slightly different times, potentially being spread across multiple storage devices.
- Block dependency risks associated with data corruption. If a source block is corrupt, it could have widespread ramifications for many files.
- Varied levels of efficiency depending on the data type and structure.
Slower system performance is a particular concern. If swift data retrieval is essential, deduplication might not be the best choice.
Deduplication use cases
Deduplication use cases cover nearly every file type. However, each file type benefits differently from deduplication. Consider file storage that likely contains identical information. A great example is installation source files, VM images or other situations where numerous copies of the same files exist. The following file and data types benefit significantly from data deduplication.
Backup files
Frequent backup jobs often contain only minor changes with lots of duplicated information.
Virtual machine files
VM disk images, ISO images and other supporting files contain identical system file information.
Email attachments
Many organizations send attachments to entire email groups, duplicating that same attachment hundreds of times.
Software binaries
Installers, CAB files and other software source files might be duplicated throughout an organization.
User documents
Office suite files, PDFs, images and other end-user data files are frequently duplicated in home directories, department folders and various collaborative storage spaces.
Code repositories
Developers might store repeated code versions since they use Git commits to manage versions.
Deduplication utilities for Windows and Linux
Depending on an organization's operating system, built-in deduplication utilities will vary.
Windows Server includes a built-in deduplication utility for NTFS. It offers several useful configuration options using PowerShell and graphical tools:
- Scheduling. Schedule deduplication actions for off-peak times using PowerShell or Task Scheduler to minimize the effect on server performance during busy times.
- Exclusions. Exclude specific file types or storage locations from the deduplication process to avoid risk to critical files.
- Age thresholds. Define file age thresholds for deduplication candidates. The default is files older than three days.
- Reporting and monitoring. Enable monitoring of the status of deduplication actions using PowerShell cmdlets like Get-DedupStatus and Get-DedupJob.
Linux users have these options for deduplication:
- Btrfs. This file system enables offline, block-based deduplication using utilities like duperemove and bedup.
- Czkawka. This tool identifies duplicate information and other unnecessary data to reclaim storage space.
- Rdfind. This tool identifies duplicate information based on file content, enabling you to manage duplicate files using other tools. It can delete duplicates or replace redundant information.
Damon Garn owns Cogspinner Coaction and provides freelance IT writing and editing services. He has written multiple CompTIA study guides, including the Linux+, Cloud Essentials+ and Server+ guides, and contributes extensively to Informa TechTarget, The New Stack and CompTIA Blogs.






