IoT data streaming can help organizations make the most of their data in situations that call for immediate action, but IT teams must have specific processes and practices in place.
IoT data streaming facilitates real-time decision making that is critical to many operations. Organizations must have tools to collect data from sensors and devices, process the data and transfer it to a database for analysis and real-time outcomes.
Data streaming can increase efficiency and prevent an impending disaster through alert automation that prompts intervention. If a sensor reads a temperature drop in a refrigerated truck, for example, IoT real-time data streaming and AI models can trigger an alert that the produce is in danger of spoiling. Organizations can also use IoT data streaming to:
detect unauthorized network access;
recognize imminent machine failure on an assembly line before the failure occurs; or
monitor patient vital signs at home for sudden changes, with an alert system that can immediately notify the doctor's office.
In other cases, real-time data streaming increases an organization's competitive advantage. For example, some clothing stores have installed smart mirrors to improve the customer experience. With smart mirrors, potential customers can find a certain look and virtually try on more items without the hassle of physically trying them on.
With many new use cases, the streaming analytics market is expected to grow from $12.5 billion in 2020 to $38.6 billion by 2025, at a compound annual growth rate of 25.2%, according to market researcher MarketsandMarkets. IoT applications and the expansion of GPS and geographic information systems that map and track events in real time drive this data streaming market.
How the data streaming process works
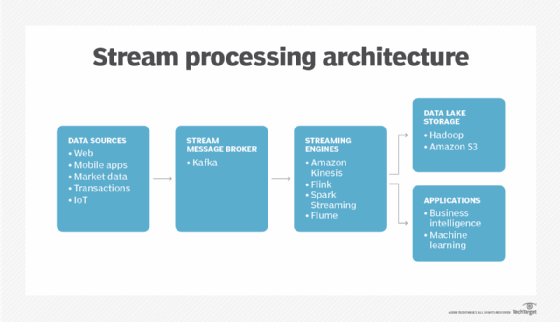
The data streaming process consists of three components: software, an operational database that runs in real time and an analytics engine that can extract the data to provide insights. In initial data stream deployments, many organizations cobble together all of these components, which requires familiarity with the process steps and knowledge of the intricacies of the tools used in each stage of the process.
The data streaming process consists of three components: software, an operational database that runs in real time and an analytics engine that can extract the data to provide insights.
The first step is to ingest the IoT data through some type of message broker or message streaming software, such as Apache ActiveMQ or Amazon Kinesis Data Streams. Once ingested, an extract, transform and load (ETL) tool prepares the data for import into an analytics database; this is typically an operational database based on a SQL platform. Organizations must then build real-time analytics and machine learning models and programs to extract business insights from the data.
Many IT departments operate with this methodology, but more automated methods and platforms have started to emerge. Some data streaming and analytics platforms or services simplify the architecture and the mechanics, such as the Splice Machine SQL database and machine learning models or the Confluent Platform.
Follow data streaming best practices
Organizations that create their process from scratch or look for an off-the-shelf offering should keep these four best practices in mind.
Choose narrow business cases. Choose business cases specific to IoT data streaming that deliver efficiencies, cost savings, customer satisfaction or increased revenues. Examples include the use of IoT data to identify which machines will fail on an assembly line, monitor network end points to prevent malicious intrusions or track the locations of the fleet.
Simplify the architecture. Organizations can simplify their data streaming architecture to speed up the time from insight to streamed data and reduce the amount of hand-coding. Tools such as Apache Kinesis Data Streams automate the data ingestion process and add additional automation to the ETL transport of data into databases and remove the need for IT to facilitate these functions with extra code. Other offerings, such as the Splice Machine database, can automatically provision test database sandboxes so a user only needs to issue a single command without the need for a data analyst to manually set up the test database.
Clean the data. Regardless of the data streaming architecture used, clean data is essential. Data cleaning can occur at the time of data ingestion and within the processing of an ETL tool. To automate portions of these processes, organizations must work with their vendors and vendors' tool sets to ensure they meet data cleaning requirements.
Address near-real-time and batch processing. Not every analytical process must be performed in real time. Some data processing can be performed at periodic, near-real-time intervals, such as every 15 minutes. In other cases, batch processing that is delivered during the day or even overnight is still very effective. Before implementation, organizations should figure out which processes require real-time or near-real-time data collection and set workflows accordingly.