IoT: Turning data into information and knowledge

In today’s information age, data is a key ingredient to success. However, while it’s important, having availability to the right data and being able to analyze it to glean critical and accurate insights is essential. As Albert Einstein once put it, “Not everything that can be counted counts, and not everything that counts can be counted.”
Don’t confuse data with information. Data, a raw set of measurements, needs to be filtered and assessed in order to be put into the learning that would be considered information. The old cliché “information overload” is really incorrect — you can have data overload, but information is always valuable. Data, by itself, is not necessarily useable. If not filtered or assessed properly, it can lead to false assumptions, as we’ve seen recently with the barrage of fake news.
In the last decade or so, the volume of data available has grown by orders of magnitude. The New York Times reported that the size of the entire digital universe in 2005 was 130 billion gigabytes. Today’s enterprise environments routinely deal with petabytes of data. And it’s coming at us faster and faster, as the number of data sources available grows each day. To get a sense of just how much things have changed, take a look at the picture below of an IBM hard drive that was loaded onto an airplane in 1956. According to the tweet by @HistoricalPics, this is a 5 MB hard drive that weighed more than 2,000 pounds! Compare that to what’s found in your smartphone today.

The variety of data types is also increasing as we start to measure mobile user activity and sensor data. What’s important to remember is that all this data means nothing unless you can turn it into intelligence, and that intelligence into action.
The power of IoT is found in its ability to capture data in real-time and being able to synthesize it quickly. When architected correctly, IoT can help transform the data into the useful information required to determine what actions should be taken next.
As stated so eloquently by Kristian J. Hammond in the Harvard Business Review, “For the most part, we know what we want out of the data. We know what analysis needs to be run, what correlations need to be found and what comparisons need to be made. By taking what we know and putting it into the hands of an automated system that can do all of this and then explain it to us in human terms, or natural language, we can achieve the effectiveness and scale of insight from our data that was always its promise but, until now, has not been delivered. By embracing the power of the machine, we can automatically generate stories from the data that bridge the gap between numbers and knowing.”
How do we go from sensing to meaning?
Prior to the emergence of IoT, analyzing the variety and volume of data provided by an assortment of devices was extremely difficult. IoT technology offers automated mechanisms for pulling machine data into data pools for analysis, with the goal of taking the next logical step in data and application management. IoT looks to not only gather and analyze the data, but also to automatically improve processes along the way.
Before I cover the steps in the process, I should probably take a moment to define a couple of terms often used when talking about data transmission in an IoT environment; northbound and southbound. Northbound data refers to the data going from the device, through the gateway and up to the cloud. It is typically telemetry data, but it can be command-and-control requests. Southbound data goes from the cloud to the gateway, or from the cloud, through the gateway, to the device. Southbound data tends to be command-and-control information, like software updates and requests for or changes to configuration parameters.
Here’s how you use northbound and southbound communication channels to go from sensing to meaning:
- Step 1: The sensors provide northbound telemetry data. Depending on the architecture, this data could be preprocessed and sent to a data store located in the field near the sensors; for example, a gateway.
- Step 2: A certain amount of analysis is done on the data at this interim point on the gateway. Here you can process the data, for example, summarizing it or transforming it to prepare it for deeper analysis in the data center or cloud. The information processed on the gateway would then be compared against previously identified patterns in a tactical analysis. This is essentially matching against correlations from historical information. Based on what patterns you find, certain actions can be taken. But you also look for things you didn’t know, trying to discover other correlations and inferences. For instance, it’s possible that you didn’t know that when the weather dropped below 10 degrees outside and prescriptions for flu medication increased by 30%, the sales of chicken soup and tissues went up over the course of the next 10 days. You may not have noticed that before. Now, this is a new conclusion you can use to make business decisions.
- Step 3: Using the new insights provided, you create a rule that is enforceable. For instance, when sensors indicate that the temperature has dropped below 10 degrees, you have the warehouse move the cans of chicken soup and boxes of tissues closer to the shipping dock. In this way, you’ve changed an inference into an action — into a business rule that can be monitored, managed and enforced.
- Step 4: In this final step, you codify the rule and deploy it in the field. In the information lifecycle graphic shown below, you can see how this is an iterative process.
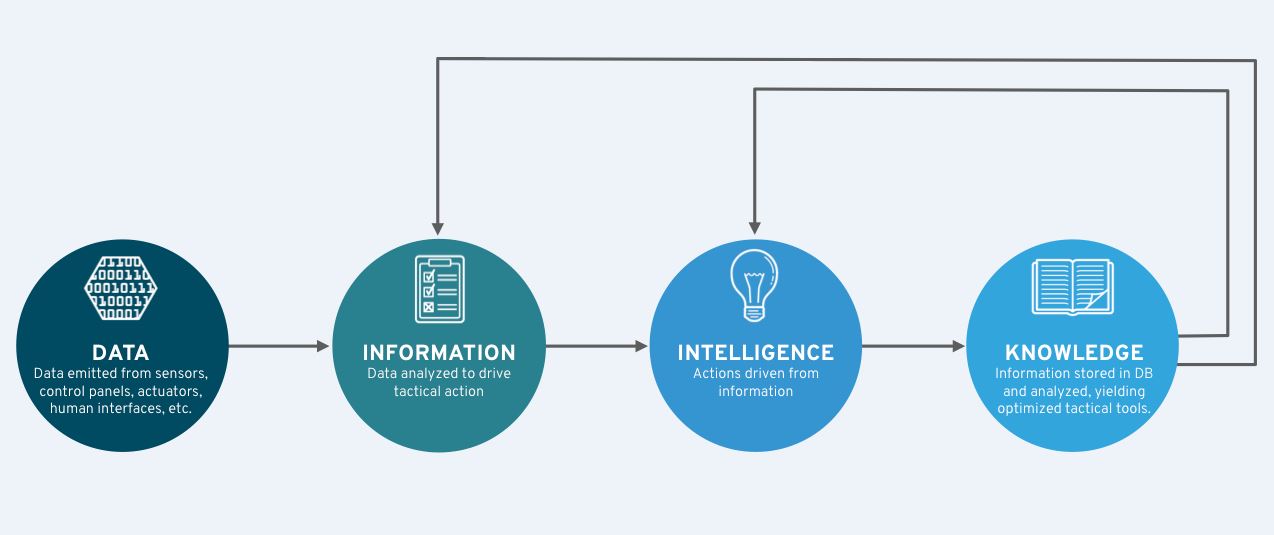
How open source helps
Open source software projects provide standardized toolkits that allow you to process data and act on it, like Camel and Drools. Apache Camel, a Java rules-based routing and mediation engine, has enterprise integration patterns that you can use to process data. It assists the developer of an IoT solution with out-of-the-box message mediation, routing and data transformation. In my opinion, the best way to use Apache Camel in an IoT context is via the Eclipse IoT working group projects, for example Eclipse Kapua and Kura.
Drools, from the JBoss community, is a business rule management system, that has built in rules templates allowing you to define what actions to take when certain conditions occur. Drools has what it takes for IoT implementations with a well-defined DSL (domain-specific language) to define rules and the scalability required with an optimized rules engine. It also comes with a GUI called Workbench that allows developers to create and edit rules very easily.
Being able to take data and transform it into information that can work for you is at the heart of any IoT effort. And, as I pointed out in my earlier blog, being able to do it through open source software will help accelerate IoT adoption and the success of IoT implementations.
All IoT Agenda network contributors are responsible for the content and accuracy of their posts. Opinions are of the writers and do not necessarily convey the thoughts of IoT Agenda.